2026-02-04
浏览次数:18ICLR2026(The Fourteenth International Conference on Learning Representations)近日发布了论文录用结果,我院共计 8 篇成果被录用。
ICLR 是深度学习领域的顶级会议,关注有关深度学习各个方面的前沿研究,在人工智能、统计和数据科学领域以及机器视觉、语音识别、文本理解等重要应用领域中发布了众多极其有影响力的论文。会议具有广泛且深远的国际影响力,居谷歌学术人工智能会议影响力排行榜前列,与 NeurIPS、ICML 并称为机器学习领域三大顶会。
以下为录用论文信息,排名不分先后。
录用论文信息
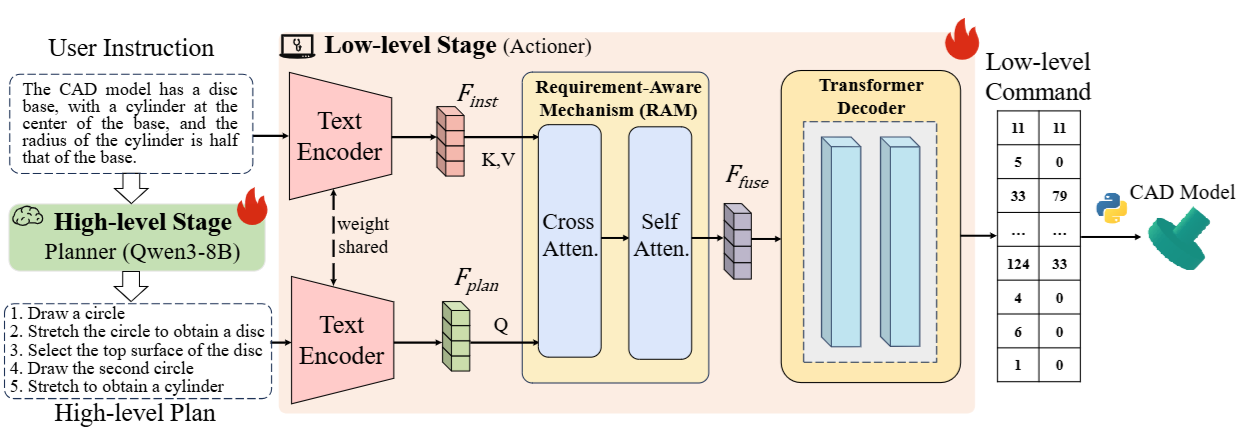
1. Plan then Act: Bi-level CAD Command Sequence Generation
作者:郭强亚,代港,刘卓蔓,黄双萍*,胡云卿,张慧源,陈添水
链接:https://openreview.net/forum?id=LhE03r8X8z
简介:计算机辅助设计 (CAD) 以其灵活性和精确性而闻名,是数字设计的基础。近年来,一些研究采用大型语言模型(LLM) 从文本指令生成参数化 CAD 命令序列。然而,我们的研究表明,基于大规模通用数据预训练的 LLM 并不擅长直接输出特定任务的 CAD 命令序列。我们不依赖于直接生成,而是引入了一种“先计划后行动”的流程。在该流程中,用户指令首先通过 LLM 解析成链式操作计划,然后利用该计划生成精确的命令序列。具体而言,我们提出了一种新的双层 CAD 命令序列生成方法——PTA。PTA 由两个关键阶段组成:高层计划生成和低层命令生成。在高层阶段,基于 LLM 的规划器完成规划过程,将用户指令解析成高层操作计划。随后,在低层生成阶段,我们引入了一个配备需求感知机制的行动器,用于从用户指令中提取设计需求(例如,尺寸、几何关系)。提取的信息用于指导底层命令序列的生成,从而提高生成序列与用户需求的匹配度。实验结果表明,我们的 PTA 在定量和定性评估中均优于现有方法。
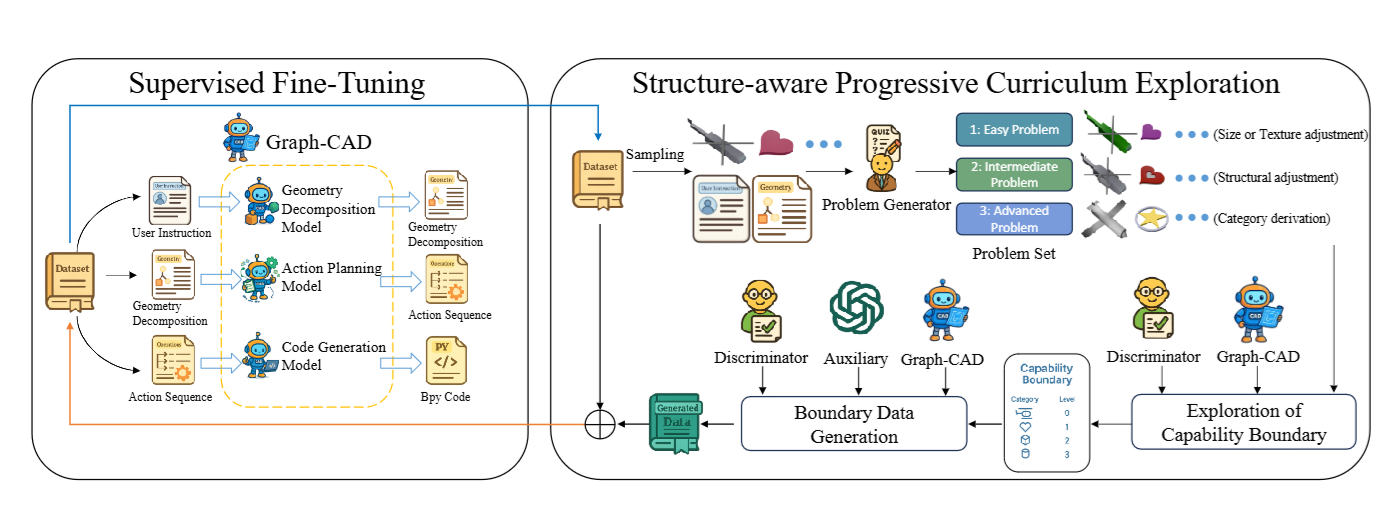
2. LearningHierarchical and Geometry-Aware Graph Representations for Text-to-CAD
作者:龚圣杰,彭文杰,陈鸿远,张刚毓,胡云卿,张慧源,黄双萍*,陈添水
链接:https://openreview.net/forum?id=oKMomThD6n
简介:文本生成 CAD 代码是一项极具挑战的长序列生成任务,现有方法通常采取“直接解码”策略,缺乏对装配层次和几何约束的显式建模,极易因早期微小错误导致复杂的装配失败。针对这一问题,本文提出学习一种层次化且几何感知的图(Graph)作为中间表示。该方法不直接将文本映射为代码,而是先预测基于装配的分解结构和几何约束,以此指导后续的操作排序和程序生成,从而有效缩小搜索空间并提高几何保真度。此外,本文还引入了结构感知的渐进式课程学习机制,显著增强了模型处理复杂装配体的能力。在包含 12K 指令的自建数据集上的实验显示,该方法在几何保真度和约束满足度方面均优于现有方法。
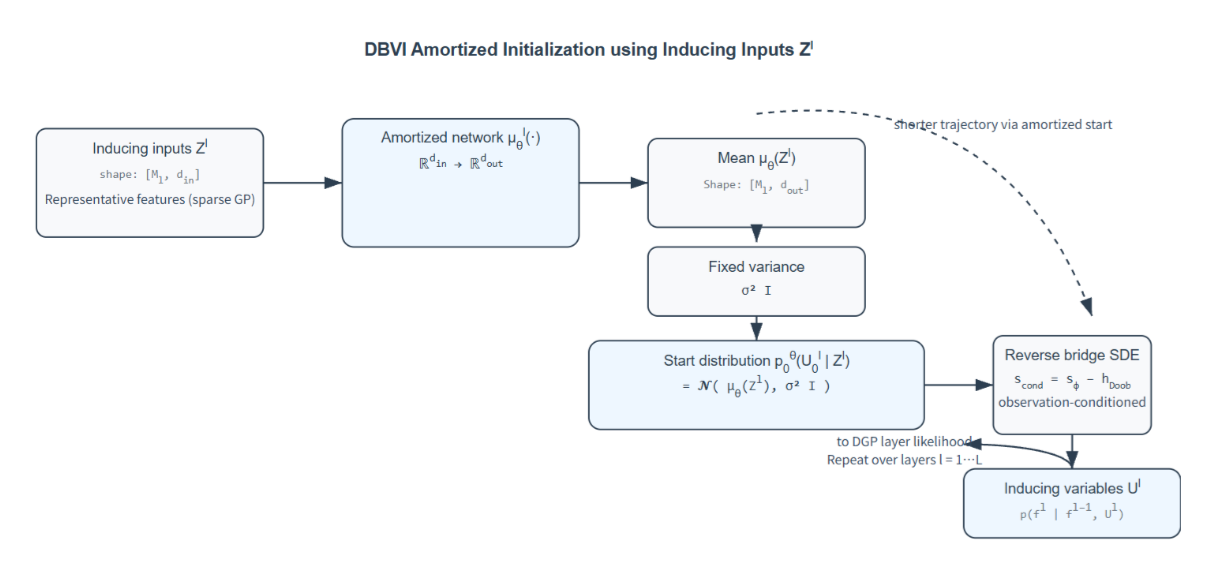
3. DiffusionBridge Variational Inference for Deep Gaussian Processes
作者:徐箭,曾德炉*,赵其宾,JohnPaisley
链接:https://openreview.net/pdf?id=zyRmy0Ch9a
简介:深度高斯过程(DGPs)具有强大的表达能力,但其后验推断(尤其是涉及诱导变量时)面临巨大挑战。现有的去噪扩散变分推断(DDVI)方法虽然利用扩散模型建模后验,但其固定的无条件起始分布导致推断效率低下且收敛缓慢。为此,本文提出了扩散桥变分推断(DBVI)。作为 DDVI的原则性扩展,DBVI 通过引入一个可学习的、依赖于数据的初始分布来启动反向扩散过程,并利用摊销神经网络和 Doob桥接扩散理论进行优化。这种方法在保留数学优雅性的同时,有效减小了后验差距。在回归、分类和图像重建任务上的实验表明,DBVI 在预测精度、收敛速度和后验质量上均显著优于现有的变分推断基线方法。
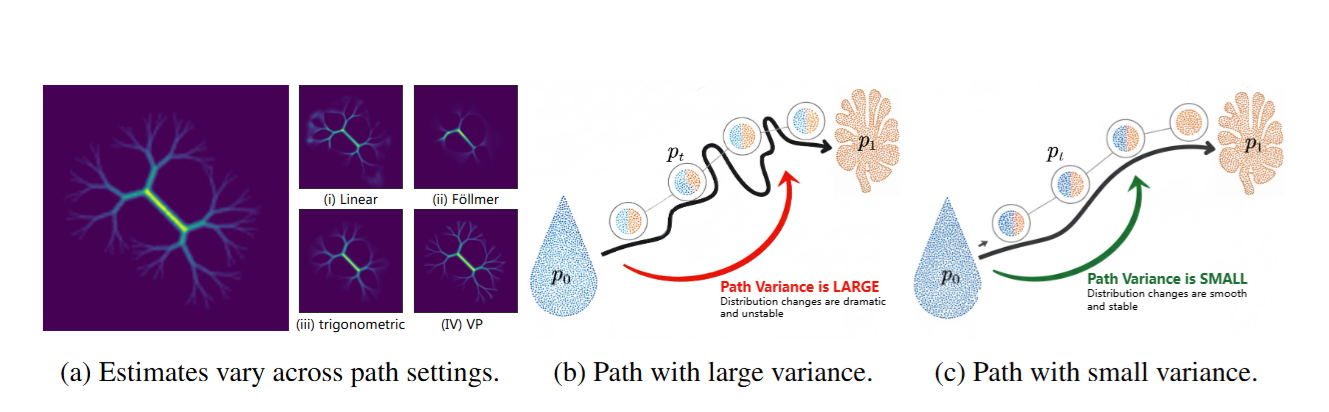
4. Don'tForget Its Variance! The Minimum Path Variance Principle for Accurate andStable Score-Based Density Ratio Estimation
作者:陈炜,李嘉诚,李仕贵,林芷琪,杨俊美,John Paisley,曾德炉*
链接:https://openreview.net/pdf?id=vf16PZJWD1
简介:基于评分的方法已成为密度比估计 (DRE) 的一个强大框架,但它们面临着一个重要的悖论:尽管理论上与路径无关,但其实际性能却严重依赖于所选的路径调度。我们通过证明易于处理的训练目标与理想的真实目标之间存在一个关键的、被忽略的项——时间评分的路径方差——来解决这个问题。为了解决这个问题,我们提出了MinPV-DRE(最小路径方差 DRE),它直接最小化这个缺失的目标。我们的主要贡献在于推导出了方差的闭式表达式,从而将一个难以处理的问题转化为一个易于处理的优化问题。通过使用灵活的Kumaraswamy 混合模型对路径进行参数化,我们的方法无需启发式选择即可学习到数据自适应的低方差路径。对整个目标进行这种有原则的优化,可以产生更准确、更稳定的估计器,在具有挑战性的基准测试中取得新的最先进成果。
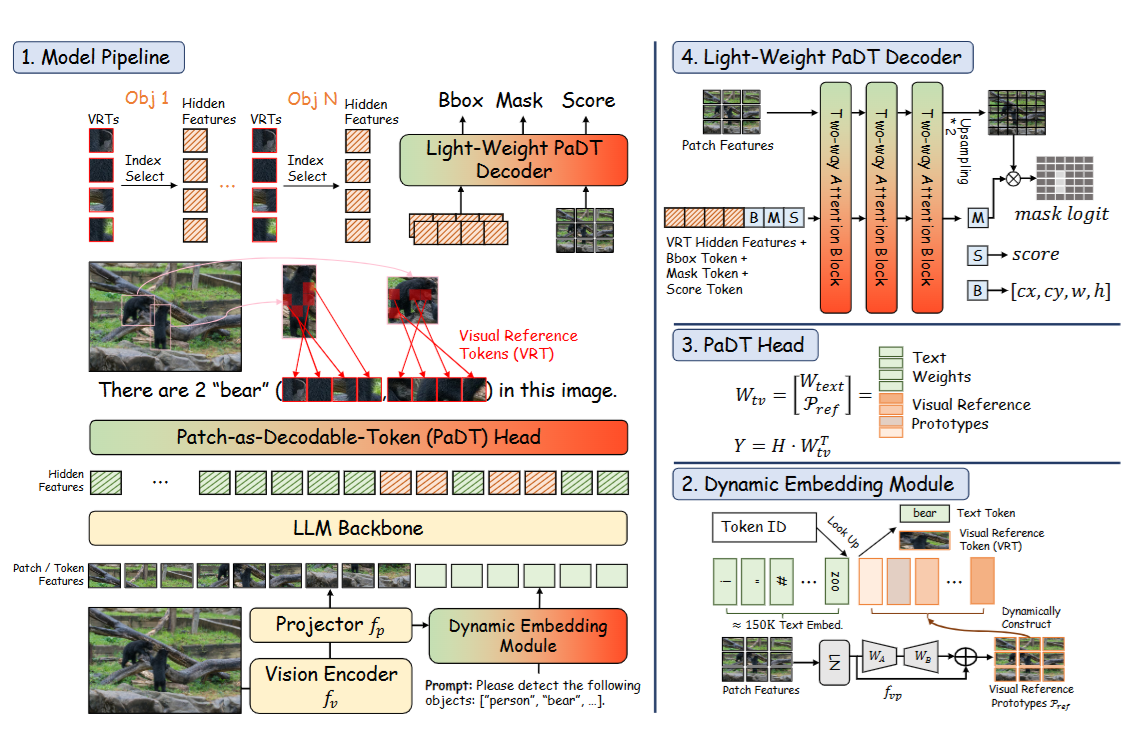
5. Patch-as-Decodable-Token:Towards Unified Multi-Modal Vision Tasks in MLLMs
作者:苏永怡,张浩杰,李仕杰,刘南清,廖京仪,潘俊毅,刘元*,邢晓芬,孙冲,李琛,Nancy F. Chen,颜水成,杨旭雷,徐迅
链接:https://openreview.net/forum?id=xF0Dcmvsl0
简介:近年来,多模态大型语言模型(MLLM)发展迅速。然而,现有的视觉任务方法通常依赖于间接表示,例如将坐标生成为文本进行检测,这限制了性能,并阻碍了分割等密集预测任务的执行。为了克服这些挑战,我们引入了基于图像块的可解码标记(PaDT),这是一种统一的范式,使 MLLM 能够直接生成文本和多样化的视觉输出。PaDT 的核心是视觉参考标记(VRT),它源自查询图像的视觉块嵌入,并与 LLM 的输出文本标记无缝交错。然后,一个轻量级解码器将 LLM 的输出转换为检测、分割和定位预测。与以往方法不同,PaDT 在每次前向传播中独立处理 VRT,并动态扩展嵌入表,从而提高了相似对象之间的定位和区分能力。我们进一步为 PaDT定制了一种训练策略,通过随机选择 VRT 进行监督微调,并引入鲁棒的逐标记交叉熵损失。我们在四项视觉感知和理解任务中的实证研究表明,即使与规模大得多的 MLLM模型相比,PaDT 也能始终如一地达到最先进的性能。
6. OCR-ReasoningBenchmark: Unveiling The True Capabilities of MLLMs in Complex Text-Rich ImageReasoning
作者:黄明鑫,施永鑫,彭德智,赖松轩,谢泽澄,金连文*
链接:https://openreview.net/pdf?id=aH7eyx64pC
简介:近年来,多模态慢思维系统取得了显著进展,在各种视觉推理任务中展现出卓越的性能。然而,由于缺乏系统的基准测试,它们在富文本图像推理任务中的能力仍未得到充分研究。为了弥补这一空白,我们提出了OCR-Reasoning,这是一个旨在系统评估多模态大型语言模型在富文本图像推理任务中表现的综合基准测试。该基准测试包含 1069个人工标注的示例,涵盖 6 项核心推理能力和 18 项富文本视觉场景下的实际推理任务。此外,与其他仅标注最终答案的富文本图像理解基准测试不同,OCR-Reasoning同时标注了推理过程。通过标注推理过程和最终答案,OCR-Reasoning不仅评估模型生成的最终答案,还评估其推理过程,从而能够对其问题解决能力进行全面分析。利用该基准测试,我们对最先进的多模态大型语言模型进行了全面的评估。我们的结果表明了现有方法的局限性。值得注意的是,即使是最先进的多模态大语言模型(MLLM)也存在相当大的困难,没有一个模型在 OCR 推理方面的准确率超过 50%,这表明文本丰富的图像推理挑战是一个亟待解决的问题。
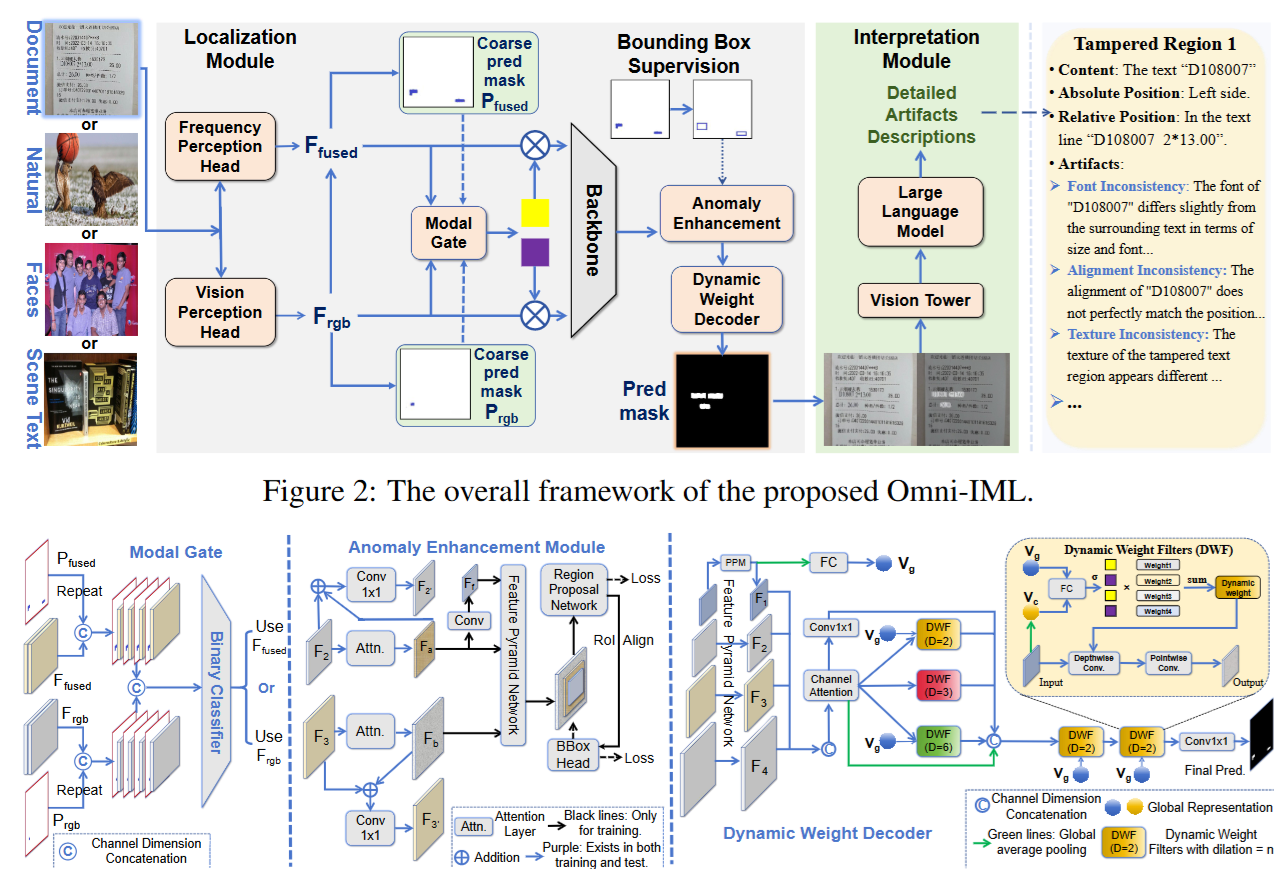
7. Omni-IML:Towards Unified Interpretable Image Manipulation Localization
作者:曲晨帆,钟亦武,郭丰俊,金连文*
链接:https://arxiv.org/pdf/2411.14823
简介:现有的图像篡改定位(IML)方法往往依赖于特定任务的设计,导致多任务联合训练时性能显著下降,难以满足实际应用需求。为此,本文提出了 Omni-IML,这是首个旨在统一多种 IML 任务的通用模型。该模型通过模态门控编码器、动态权重解码器和异常增强模块三个关键组件,实现了对不同篡改类型的高效泛化。此外,为了增强结果的可解释性,本文还构建了包含自然语言描述的大规模高质量数据集 Omni-273k,并设计了相应的解释模块。实验结果表明,Omni-IML在四个主流 IML 任务上均达到了最先进的性能,为通用图像取证模型的研究提供了新的方向。
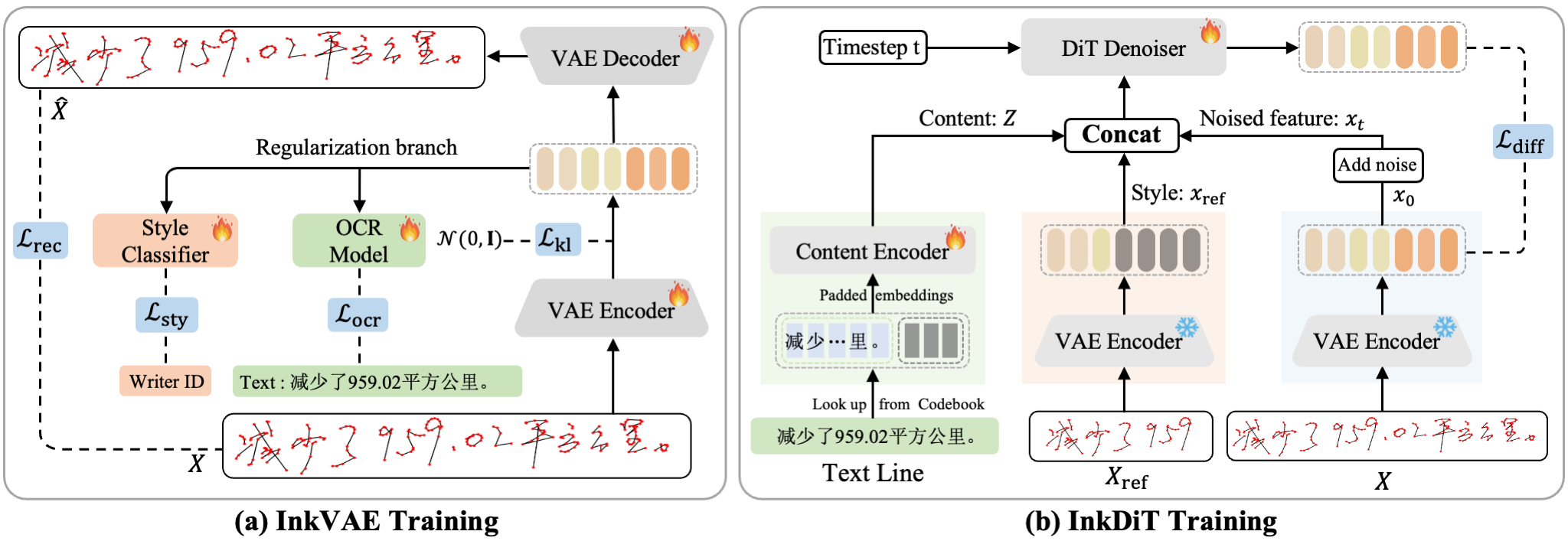
8. DiffInk:Glyph- and Style-Aware Latent Diffusion Transformer for Text to Online HandwritingGeneration
作者:潘炜,何汇国,郑晓怡,史毅临,金连文*
链接:https://arxiv.org/abs/2509.23624
简介:深度生成模型推动了文本到在线手写生成(TOHG)的发展,其目标是根据文本输入和风格参考合成逼真的笔迹轨迹。然而,大多数现有方法仍然主要关注字符或词级生成,导致在应用于整行文本时效率低下且缺乏整体结构建模。为了解决这些问题,我们提出了DiffInk,这是首个用于整行手写生成的潜在扩散Transformer 框架。我们首先引入了 InkVAE,一种新型的序列变分自编码器,它通过两个互补的潜在空间正则化损失进行增强:(1)基于 OCR 的损失,用于确保字形级别的准确率;(2)风格分类损失,用于保持书写风格。这种双重正则化产生了一个语义结构化的潜在空间,其中字符内容和书写风格被有效地解耦。然后,我们引入了InkDiT,一种新型的潜在扩散Transformer,它融合了目标文本和参考风格,以生成连贯的笔迹轨迹。实验结果表明,DiffInk在字形精度和样式保真度方面均优于现有最先进方法,同时显著提高了生成效率。
(文/黄双萍、曾德炉、刘元、金连文,初审/黄双萍,复审/曾抒姝,终审/李石槟)