2025-03-14
浏览次数:10Recently, 13 academic papers by our graduate students were successfullyaccepted by top-tier AI conferences CVPR/ICLR/AAAI (2025), fully demonstratingour institute’s significant progress in cutting-edge AI research and theeffectiveness of cultivating graduate students' academic innovation capabilities.
The Conference on Computer Vision and Pattern Recognition (CVPR) is apremier international conference in the field of computer vision. CVPR employsa rigorous peer-review process and attracts submissions from top universities,research institutions, and industry worldwide. Its papers have a profoundimpact in computer vision and AI. Recognized as a CCF-A conference by the ChinaComputer Federation (CCF), CVPR is ranked alongside ICCV and ECCV as one of thethree top-tier conferences in computer vision, representing the highestacademic standards in the field. This year, CVPR 2025 received over 12,000valid submissions, with an overall acceptance rate of ~25%, while our instituteachieved an acceptance rate of ~35%.
The International Conference on Learning Representations (ICLR) is aleading conference in deep learning. ICLR adopts an open-review system andattracts submissions from top global institutions, with its papers holdingsignificant influence in AI. Also classified as a CCF-A conference, ICLR standsalongside NeurIPS and ICML as a flagship event in the field. ICLR 2025 receivednearly 11,500 valid submissions, with an overall acceptance rate of ~32.08%,while our institute achieved an exceptional rate of ~75%.
The Association for the Advancement of Artificial Intelligence (AAAI) isone of the most prestigious and long-standing international AI conferences,covering a broad spectrum of AI research. As a CCF-A conference, it ranks 4thin H5-index among top AI publications per Google Scholar Metrics. This year,AAAI 2025 received 12,957 submissions, accepting 3,032 papers (acceptance rate:23.4%), with our institute achieving a rate of ~40%.
01 Monocular and Generalizable Gaussian Talking Head Animation
Authors: Shengjie Gong (South China University of Technology), Haojie Li(South China University of Technology), Jiapeng Tang (Technical University ofMunich), Dongming Hu (South China University of Technology), Shuangping Huang*(South China University of Technology), Hao Chen (South China University ofTechnology), Tianshui Chen (Guangdong University of Technology), Zhuoman Liu(The Hong Kong Polytechnic University)
Paper Abstract
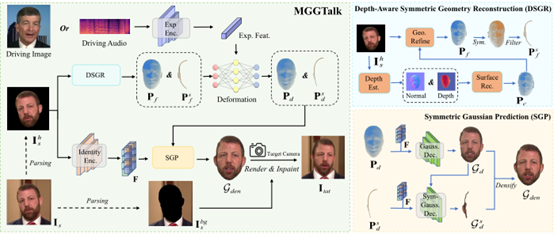
In this study, we propose a monocular and generalizable Gaussian talkinghead animation method (MGGTalk), which requires only a monocular dataset andcan generalize to unseen identities without personalized retraining. Comparedto previous 3D Gaussian Splatting (3DGS)-based approaches—which typically relyon scarce multi-view datasets or cumbersome per-subjecttraining/inference—MGGTalk significantly enhances the practicality and broadapplicability of this technology.
However, the absence of multi-view data and personalized trainingintroduces major challenges due to incomplete geometric and appearanceinformation. To address these, MGGTalk leverages depth-aware facial symmetry toenhance geometric and appearance features. First, we extract per-pixelgeometric cues from depth estimation, combined with symmetry operations andpoint cloud filtering, to ensure 3DGS possesses complete and accuratepositional parameters. Subsequently, we adopt a two-stage strategy with symmetrypriors to predict the remaining 3DGS parameters: initially predicting Gaussianparameters for visible facial regions in the source image, then refiningpredictions for occluded regions using these parameters.
Extensive experiments demonstrate that MGGTalk outperformsstate-of-the-art methods across multiple metrics, achieving superiorperformance.
02 MPDrive: Improving SpatialUnderstanding with Marker-Based Prompt Learning for Autonomous Driving
Authors: Zhiyuan Zhang (SouthChina University of Technology), Xiaofan Li (Baidu), Zhihao Xu (South ChinaUniversity of Technology), Wenjie Peng (South China University of Technology),Zijian Zhou (King's College London), Miaojing Shi (Tongji University), ShuangpingHuang* (South China University of Technology)
Paper Abstract
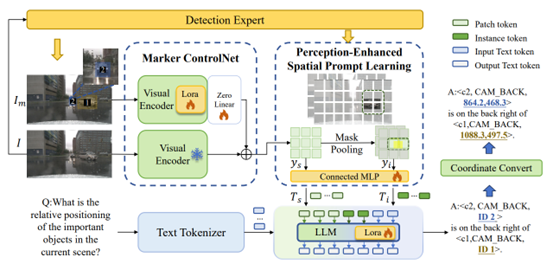
Autonomous Driving Visual Question Answering (AD-VQA) aims to answerperception-, prediction-, and planning-related questions based on given drivingscene images, a task that heavily relies on models' spatial reasoningcapabilities. Previous approaches typically represent spatial informationthrough textual coordinate descriptions, creating a semantic gap between visualcoordinate representations and linguistic expressions. This oversightcompromises accurate spatial information transmission and increasesrepresentational complexity.
To address this challenge, we propose MPDrive, a novel token-based promptlearning framework that represents spatial coordinates using compact visualtokens. This approach ensures linguistic consistency while enhancing visualperception and spatial expression accuracy in AD-VQA. Specifically, wetransform complex textual coordinate generation into direct text-based visualtoken prediction by leveraging detection experts to overlay target regions withnumerical labels, creating tokenized images. The framework integrates originalimages with tokenized images as scene-level features, which are then combinedwith detection priors to derive instance-level features. By fusing thesedual-granularity visual prompts, we effectively activate large language models'(LLMs) spatial awareness capabilities.
Extensive experiments demonstrate that MPDrive outperformsstate-of-the-art methods across multiple metrics, achieving superiorperformance.
03 DocLayLLM: An EfficientMulti-modal Extension of Large Language Models for Text-rich DocumentUnderstanding
Authors: Wenhui Liao (South China University of Technology), Jiapeng Wang(South China University of Technology), Hongliang Li (South China University ofTechnology), Chengyu Wang (Alibaba Cloud Computing Co., Ltd.), Jun Huang(Alibaba Cloud Computing Co., Ltd.), Lianwen Jin* (South China University ofTechnology)
Paper Abstract
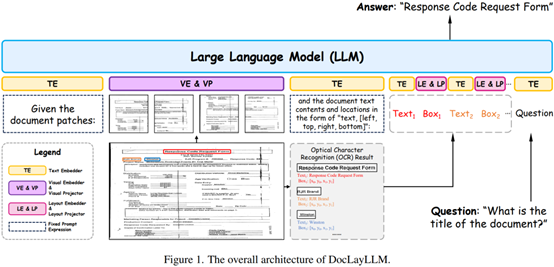
Visual-rich document understanding involves the parsing and comprehensionof documents with complex layout structures, a process requiring theintegration of multimodal information. However, this field faces significantchallenges in generalizability and adaptability when handling diverse documentlayouts and types. To address these challenges, we propose DocLayLLM, whichenhances large language models (LLMs) by incorporating lightweight visualtokens and 2D positional encodings. This approach effectively leverages thegeneralizability and adaptability of LLMs while achieving efficient multimodalextension.
Furthermore, we integrate chain-of-thought (CoT) techniques and proposetwo novel training strategies: CoT pre-training and CoT annealing, whichsignificantly improve the model's training efficiency and performance.Experimental results demonstrate that our method outperforms existing largedocument understanding models while requiring substantially fewer computationalresources.
04 Guiding Human-ObjectInteractions with Rich Geometry and Relations
Authors: Mengqing Xue (South China University of Technology), Yifei Liu(South China University of Technology), Ling Guo (South China University ofTechnology), Shaoli Huang (Tencent AI Lab), Changxing Ding* (South ChinaUniversity of Technology)
Paper Abstract
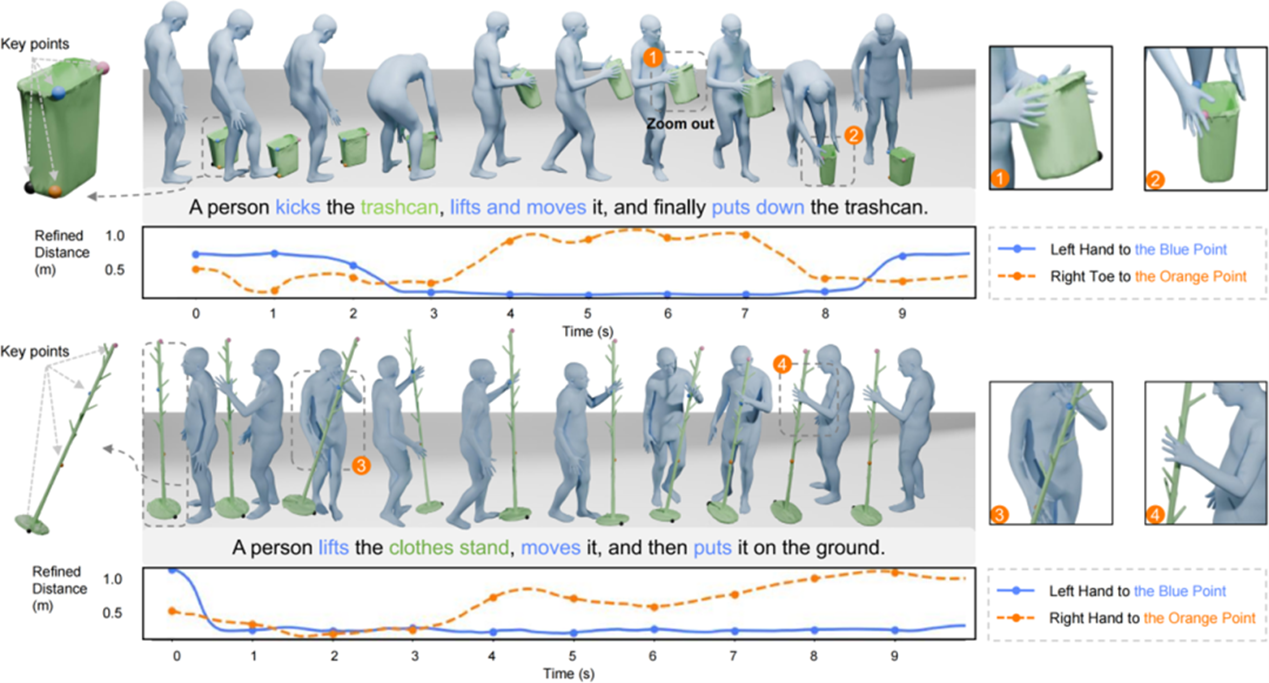
This paper presents ROG, a novel diffusion-based, text-driven frameworkfor human-object interaction (HOI) motion generation. By explicitly modelingthe inherent spatiotemporal relationships in HOI, our method significantlyenhances the realism of generated motions.
To achieve efficient object representation, we identifyboundary-sensitive and geometrically rich keypoints from object meshes,ensuring comprehensive characterization of object geometry. Theserepresentations are then used to construct an Interaction Distance Field (IDF),which robustly captures dynamic HOI properties. Furthermore, we propose arelation-aware diffusion model incorporating spatiotemporal attentionmechanisms to better understand complex HOI dependencies. The model optimizesthe IDF features of generated motions, guiding the generation process towardrelation-aware and semantically aligned actions.
Extensive evaluations demonstrate that ROG substantially outperformsstate-of-the-art methods in terms of motion realism and semantic accuracy forHOI generation.
05 Modeling Thousands of HumanAnnotators for Generalizable Text-to-Image Person Re-identification
Authors: Jiayu Jiang (South China University of Technology), ChangxingDing* (South China University of Technology), Wentao Tan (South ChinaUniversity of Technology), Junhong Wang (South China University of Technology),Jin Tao (South China University of Technology), Xiangmin Xu (South ChinaUniversity of Technology)
Paper Abstract
This paper proposes Human Annotator Modeling (HAM), a novel approachaddressing the text annotation diversity challenge in text-image cross-modalperson re-identification (ReID). While existing multimodal large languagemodels (MLLMs) typically generate stylistically homogeneous image descriptions,limiting their practical generalization, HAM enriches MLLM-generated textdiversity by explicitly modeling thousands of individual human annotators frommanual annotation datasets.
Our method first extracts style features from human-written descriptionsand clusters these features, then employs prompt learning to equip MLLMs withstyle-adaptive instruction-following capabilities. We further propose UniformPrototype Sampling (UPS) to uniformly sample the defined style feature space,capturing broader human annotation styles and significantly enhancing MLLMs'stylistic diversity in text generation.
Experimental results demonstrate that our constructed HAM-PEDES datasetachieves superior performance across multiple benchmarks, substantiallyimproving text-image cross-modal ReID model generalization while dramaticallyreducing reliance on large-scale manual annotations. This work provides newperspectives and methodologies for future research in multimodal learning.
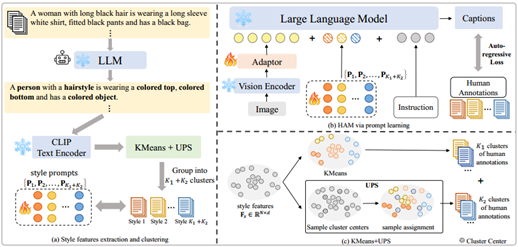
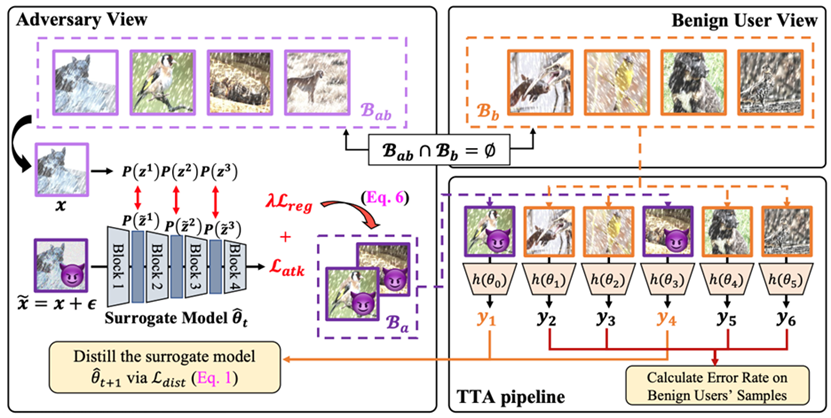
06 Effortless Active Labeling forLong-Term Test-Time Adaptation
Authors: Guowei Wang (South China University of Technology), ChangxingDing* (South China University of Technology)
Paper Abstract
This paper presents an efficient active learning-based test-timeadaptation (TTA) method, focusing on selecting the most valuable samples forannotation. We propose a feature perturbation strategy that identifiesinformative samples by measuring the magnitude of prediction confidence changesunder slight perturbations. The key insight is that samples near the boundarybetween source and target domain distributions are most informative and can beeffectively learned through single-step optimization.
Additionally, we introduce a gradient norm-based debiasing strategy todynamically balance the influence of labeled and unlabeled samples on modeloptimization. Extensive experiments on multiple benchmark datasets demonstratethat our method significantly reduces annotation costs while outperformingstate-of-the-art approaches. For instance, on ImageNet-C, our method achieves a6.8% lower average error rate than baseline methods when annotating just onesample per batch. Remarkably, it maintains superior performance even whenannotating only one sample every five batches.
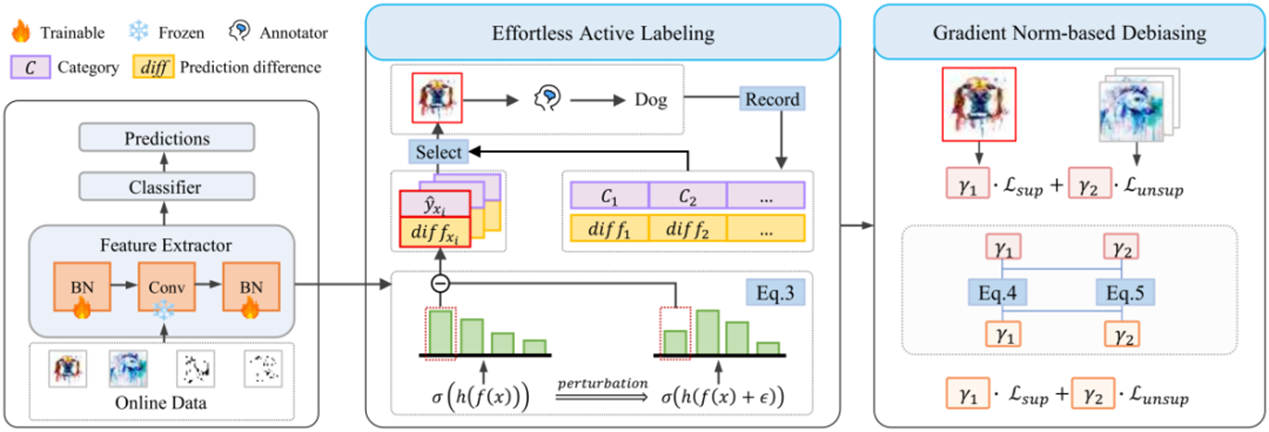
07 Mini-Monkey: Alleviating theSemantic Sawtooth Effect for Lightweight MLLMs via Complementary Image Pyramid
Authors: Mingxin Huang (SouthChina University of Technology), Yuliang Liu (Huazhong University of Scienceand Technology), Dingkang Liang (Huazhong University of Science andTechnology), Lianwen Jin* (South China University of Technology), Xiang Bai(Huazhong University of Science and Technology)
Paper Abstract
To address the semantic fragmentation caused by partitioning strategiesin multimodal large models, this paper proposes a plug-and-play ComplementaryImage Pyramid (CIP) module, significantly enhancing high-resolution imageprocessing capability. CIP generates complementary image hierarchies thatsimultaneously preserve fine-grained local features and global contextualinformation, effectively mitigating incoherence induced by image splitting.
Furthermore, we introduce a Scale Compression Mechanism (SCM) to optimizecomputational resource utilization. Integrating CIP and SCM, we developMiniMonkey—a lightweight multimodal large model.Experimental results demonstrate MiniMonkey's superior performance in bothgeneral scenarios and complex document image analysis, notably achieving 806points on OCRBench, outperforming larger models like InternVL-2-8B.
CIP exhibits broad applicability, seamlessly integrating into diversemultimodal architectures to enhance performance, offering a novel technicalparadigm for high-resolution image understanding.
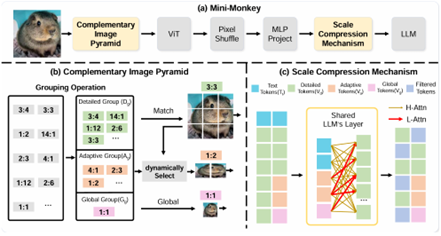
08 Efficient and Context-AwareLabel Propagation for Zero-/Few-Shot Training-Free Adaptation ofVision-Language Model
Authors: Yushu Li (South China University of Technology), Yongyi Su(South China University of Technology), Adam Goodge (ASTAR - Agency forScience, Technology and Research), Kui Jia (The Chinese University of HongKong, Shenzhen), Xu Xun (ASTAR - Agency for Science, Technology and Research)
Paper Abstract
Vision-Language Models (VLMs) have revolutionized machine learning by leveraginglarge-scale pretrained models for diverse downstream tasks. Despiteimprovements in labeling, training, and data efficiency, many state-of-the-artmodels still require task-specific hyperparameter tuning and fail to fullyutilize test samples. To address these challenges, we propose a graph-basedefficient adaptation and inference method.
Our approach dynamically constructs graphs from textual prompts, few-shotexamples, and test samples, enabling label propagation-based inference withouttask-specific adjustments. Unlike existing zero-shot label propagationtechniques, our method eliminates the need for additional unlabeled supportsets and effectively leverages the test sample manifold through dynamic graphexpansion. We further introduce a context-aware feature reweighting mechanismto enhance task adaptation accuracy. Additionally, our framework supportsefficient graph extension, facilitating real-time inductive inference.
Extensive evaluations on downstream tasks—including fine-grained classification and out-of-distributiongeneralization—demonstrate the effectiveness of ourapproach.
09 On the Adversarial Risk of TestTime Adaptation:An Investigation into Realistic Test-Time Data Poisoning
Authors:Yongyi Su (South China University of Technology), Yushu Li (SouthChina University of Technology), Nanqing Liu (Southwest Jiaotong University),Kui Jia (The Chinese University of Hong Kong, Shenzhen), Xulei Yang (ASTAR),Chuan-Sheng Foo (ASTAR), Xu Xun (A*STAR)
Paper Abstract
Test-time adaptation (TTA) enhances model generalization by updatingweights during inference using test data, yet this practice also introducesadversarial risks. Existing studies show that TTA's performance on normalsamples may degrade when exposed to carefully crafted adversarial test samples(i.e., test-time poisoning data). However, if poisoning data generation relieson overly strong assumptions, the perceived adversarial risk could beexaggerated.
In this work, we first revisit realistic assumptions for test-time datapoisoning, including white-box vs. gray-box attacks, access to normal data, andattack sequence. We then propose a more effective and practical attack methodcapable of generating poisoning samples without accessing normal data, derivingan effective in-distribution attack objective function. Furthermore, we designtwo novel attack objectives specifically targeting TTA. Through benchmarkingexisting attacks, we reveal that TTA methods exhibit greater robustness thanpreviously believed. Finally, we explore defensive strategies to advance thedevelopment of adversarially robust TTA approaches.
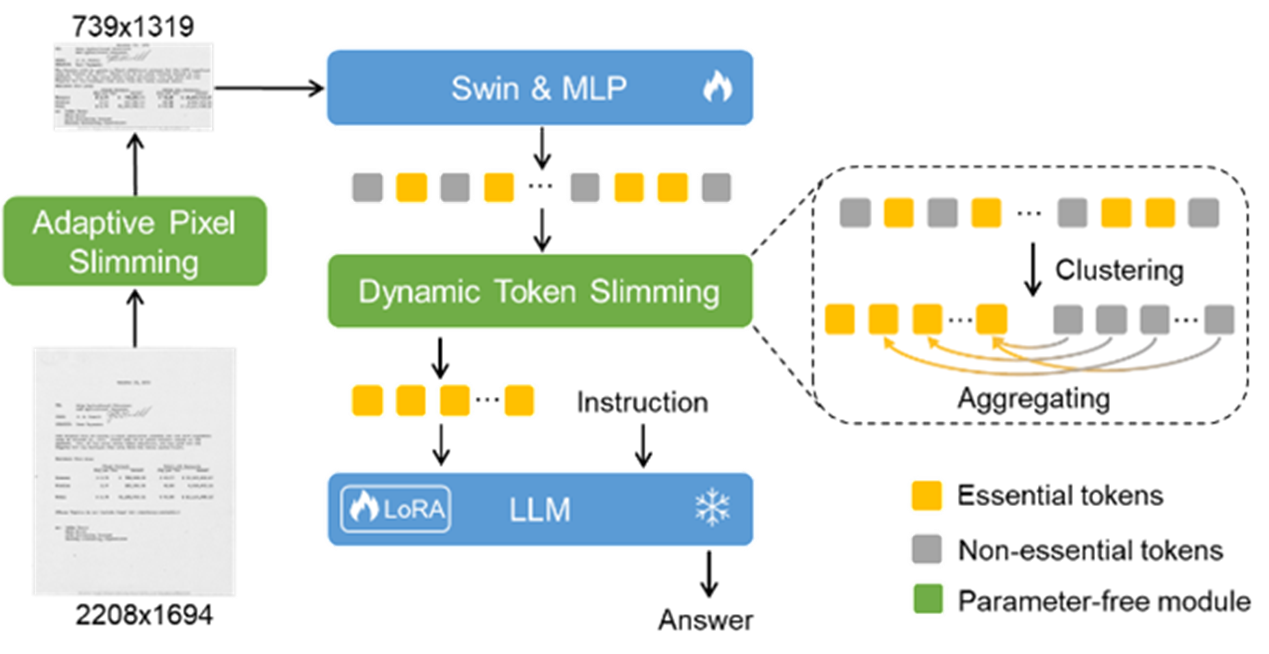
10 DocKylin: A Large MultimodalModel for Visual Document Understanding with Efficient Visual Slimming
Authors: Jiaxin Zhang (South China University of Technology), Wentao Yang(South China University of Technology), Songxuan Lai (Huawei Cloud), ZechengXie (Huawei Cloud), Lianwen Jin* (South China University of Technology)
Paper Abstract
Multimodal Large Language Models (MLLMs) have recently achieved rapiddevelopment, but they still face significant limitations in Visual DocumentUnderstanding (VDU) tasks: insufficient input resolution leads to loss offine-grained information, while high-resolution input results in highlyredundant pixels and inefficient visual token compression, posing tremendouschallenges to model efficiency and long-context modeling capabilities.Additionally, the fixed-resolution compression commonly adopted by currentmethods tends to cause text deformation.
To address these issues, this paper proposes the DocKylin model, whichachieves efficient document image redundancy reduction through dynamic visualcompression technology. The model is based on a parameter-free adaptivemechanism that combines gradient analysis and rule-based design to cropredundant regions at the pixel level, supports dynamic resolution encoding toadapt to document aspect ratio characteristics, and employs intelligentclustering to select key visual tokens, significantly reducing redundantcomputations while preserving core features. Experiments verify that DocKylindemonstrates outstanding performance advantages on mainstream benchmarks, andits modular design allows for convenient migration to other MLLMs, providing aninnovative solution that balances both efficiency and accuracy for complexdocument understanding tasks.
11 Revisiting Tampered Scene TextDetection in the Era of Generative AI
Authors: Chenfan Qu (South China University of Technology), Yiwu Zhong(The Chinese University of Hong Kong), Fengjun Guo (Shanghai Hehe InformationTechnology Co., Ltd.), Lianwen Jin* (South China University of Technology)
Paper Abstract
In this era of rapid development of generative AI, new text image editingalgorithms are emerging continuously. However, current text image tamperingdetection methods only perform well on tampering techniques seen in thetraining set, while their performance drops dramatically when detectingtampered text generated by unseen text editing models. This poses significantsecurity risks.
To address the generalization problem for unknown AIGC text tamperingmethods, this paper constructs a new dataset containing 8 types of AIGCtampering techniques, which for the first time enables simultaneous evaluationof models across different tampering generation methods and image styles. Tosolve the problems of high cost and limited quantity in acquiring high-qualityAIGC text tampering data, this paper proposes a texture jitter trainingparadigm, which significantly alleviates the shortage of high-quality trainingdata and guides the model to improve cross-domain generalization by focusing ontexture anomalies. This paper also proposes a difference-aware modelingframework to further enhance the model's generalization capability fortampering by unknown AIGC methods.

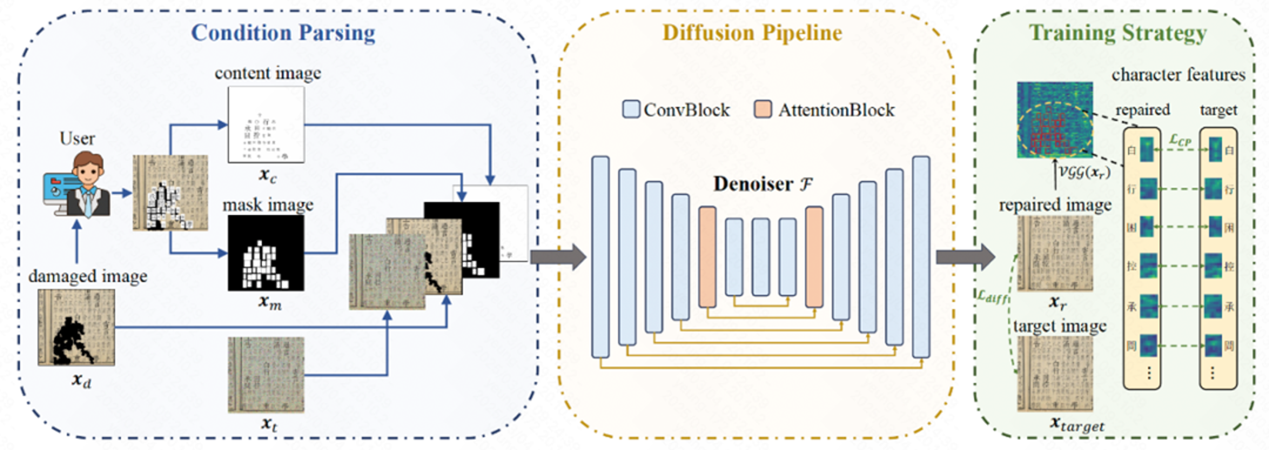
12 Predicting the OriginalAppearance of Damaged Historical Documents
Authors: Zhenhua Yang (South China University of Technology), Dezhi Peng(South China University of Technology), Yongxin Shi (South China University ofTechnology), Yuyi Zhang (South China University of Technology), Chongyu Liu(South China University of Technology), Lianwen Jin* (South China University ofTechnology)
Paper Abstract
Ancient documents contain rich cultural information, but over time theyhave suffered severe damage, including character loss, paper deterioration, andink erosion. However, existing document processing methods mainly focus onoperations such as binarization and enhancement, while neglecting therestoration of these damages. To address this, we propose a new task calledHistorical Document Repair (HDR), which aims to predict the original appearanceof damaged ancient documents.
To fill the gap in this field, we have constructed a large-scale datasetHDR28K and proposed a diffusion model-based restoration network DiffHDR forancient document repair. Specifically, HDR28K contains 28,552 pairs ofdamaged-restored images, providing character-level labels and various styles ofdamage. Furthermore, DiffHDR incorporates semantic and spatial informationbased on the diffusion model, and carefully designs character-aware loss toensure contextual coherence and visual consistency.
Experimental results demonstrate that DiffHDR significantly outperformsexisting methods and exhibits outstanding performance when processing realdamaged documents. Notably, DiffHDR can also be extended to document editingand text block generation, showing remarkable flexibility and generalizationcapability. We believe this research can pioneer new directions in documentprocessing and contribute to the preservation of precious cultures andcivilizations.
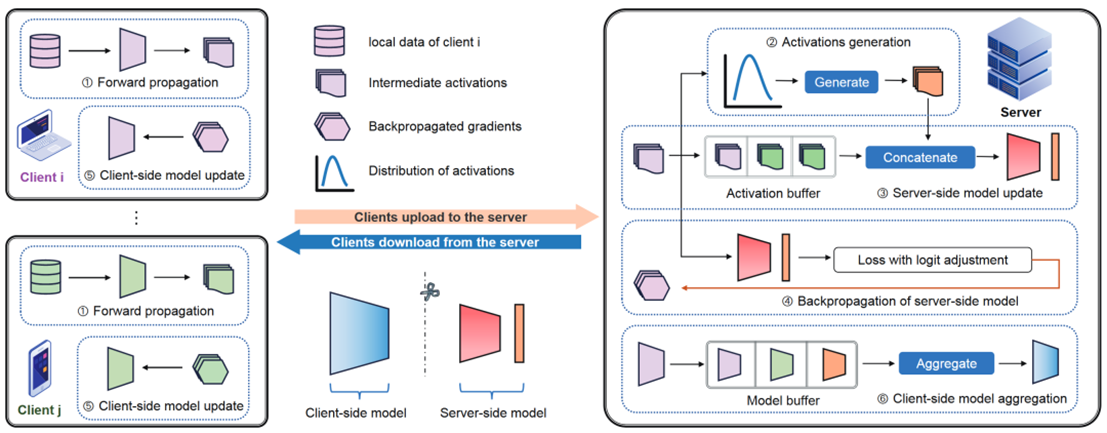
13 GAS: GenerativeActivation-Aided Asynchronous Split Federated Learning
Authors: Jiarong Yang (South ChinaUniversity of Technology), Yuan Liu (South China University of Technology)
Paper Abstract
Split federated learning deploys the model separately on the client andserver sides for collaborative training, effectively reducing the computationalburden on clients. Recent studies in split federated learning assumesynchronous transmission of activations and client models between clients andservers. However, due to computational heterogeneity among clients and networkfluctuations, servers often face asynchronously arrived activations and clientmodels, which reduces the training efficiency of split federated learning.
To address this challenge, this study proposes an asynchronous splitfederated learning framework, where the server embeds activation buffers andmodel buffers to manage asynchronously transmitted activations and clientmodels respectively. Based on dynamically updated activation distributions, wedevelop an adaptive activation generation algorithm that produces compensatedactivations through a deviation-aware mechanism to ensure the accuracy ofglobal model updates. Theoretical analysis derives tighter convergence bounds.Experimental results demonstrate the effectiveness of the proposed method.
Text & Images: Shuangping Huang, Lianwen Jin, Yuan Liu, ChangxingDing
Preliminary Review: Weiying Yan
Secondary Review: Shushu Zeng
Final Review: Shiping Li