在生成式推荐方向,组里再添一项新成果。博士生吴斌权的论文《Unifying Behavior Modeling and Semantic Generation for Generative Recommendation》近日被国际数据挖掘与知识发现大会(ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2026)录用。这是斌权在 KDD2026 以第一作者录用的第二篇论文,也是组里首次有同学在同一 CCFA 类会议上以一作同时中稿两篇。KDD 作为数据挖掘领域的顶级国际会议、CCF A 类会议,汇聚全球数据挖掘与知识发现领域的前沿研究成果。
论文题目:Unifying Behavior Modeling and Semantic Generation for Generative Recommendation
作者:Binquan Wu, Xinbo Chen, Yicheng Luo, Yuhao Ke, Jingye Li, Kun Zeng, Qianli Ma*
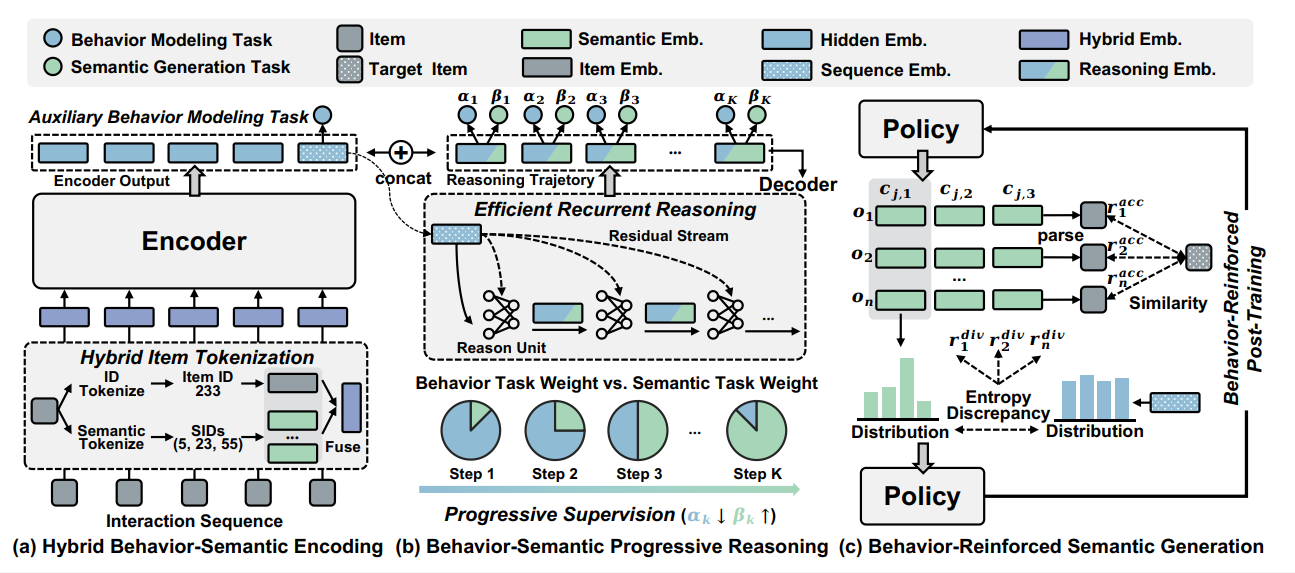
论文简介:生成式推荐(Generative Recommendation, GR)为每个物品分配由内容生成的语义 ID(Semantic IDs, SIDs),并借助序列到序列模型,根据用户历史会话生成目标物品的语义 ID,其性能通常优于仅依赖行为建模的序列推荐(Sequential Recommendation, SR)方法。然而,生成式推荐方法存在"语义偏好偏差"问题:模型倾向于推荐语义相似的物品,却忽视了那些语义相似度弱、但具有行为相关性的物品——而后者恰是序列推荐通过行为建模能够更有效捕捉的。为此,我们提出了 OMG,一种将行为建模与语义生成相统一的生成式推荐方法,使推荐结果能够无缝融合两类信息。首先,我们引入混合行为-语义编码(Hybrid Behavior-Semantic Encoding),使模型在编码交互序列时,除语义关联外还能捕捉显著的用户行为模式,从而召回那些具有一定行为相关性但语义相似度弱的物品;其次,我们提出行为-语义渐进推理(Behavior-Semantic Progressive Reasoning),迭代地精炼编码器输出,逐步将其从行为空间转换到语义空间,并利用由此得到的推理轨迹引导语义 ID 的解码,从而弥合行为建模与语义生成之间的鸿沟;最后,我们采用行为强化的语义生成(Behavior-Reinforced Semantic Generation),引入带有行为感知奖励的强化学习,以增强模型的推理能力,并使解码器的生成过程更好地与用户行为对齐。在多个基准数据集上的实验表明,OMG 始终优于对比方法。
GitHub链接:https://anonymous.4open.science/r/OMG/