近日,国际学习表征会议(International Conference on Learning Representations, ICLR 2026)论文接收结果公布,组里博士生黎泊远的研究成果《Learning Recursive Multi-Scale Representations for Irregular Multivariate Time Series Forecasting》。ICLR一直被认为是深度学习领域的顶级国际会议之一,于今年被列入CCF A类会议的名单。本次会议将于2026年4月23日-27日在里约热内卢举行,展示人工智能与深度学习领域的最新进展和突破性研究。
论文题目:Learning Recursive Multi-Scale Representations for Irregular Multivariate Time Series Forecasting
作者:Boyuan Li, Zhen Liu, Yicheng Luo, Qianli Ma*
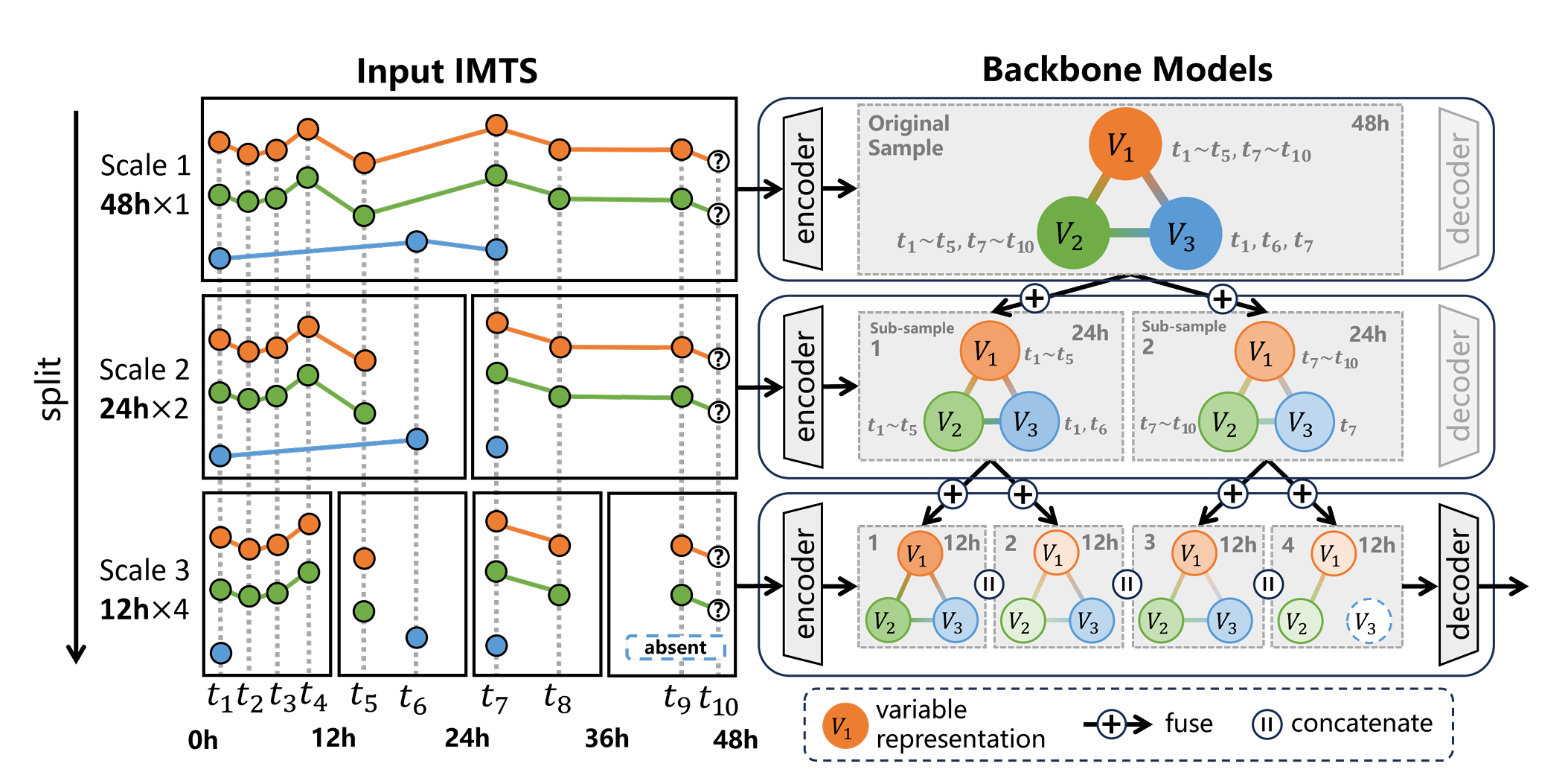
论文简介:不规则多变量时间序列(IMTS)的特点是连续时间戳之间的间隔不均匀,这些时间点携带着对学习时间和变量依赖关系具有价值和信息量的采样模式信息。此外,IMTS 在多个时间尺度上常表现出多样的依赖性。然而,许多现有的多尺度IMTS方法通过重采样获得粗序列,这可能会改变原始时间戳并干扰采样模式信息。为应对这一挑战,我们提出了ReIMTS,这是一种用于不规则多变量时间序列预测的递归多尺度建模方法。ReIMTS 不进行重采样,而是保持时间戳不变,递归地将每个采样拆分为时间段逐渐缩短的子采样。基于这些长到短子样本的原始采样时间戳,提出了一种不规则性感知的表示融合机制,以捕捉全局到局部的依赖关系,从而实现准确预测。大量实验显示,不同模型和现实数据集中预测任务的平均性能提升达27.1%。
GitHub链接:https://github.com/Ladbaby/PyOmniTS