| 人脸表情迁移:技术综述与前沿探索 |
| 发布时间: 2025-06-24 浏览次数: 10 |
|
图/文:罗旺宗 人脸表情迁移:技术综述与前沿探索 在人工智能与计算机视觉飞速发展的当下,人脸表情迁移技术正成为数字人、影视特效、虚拟现实等领域的核心驱动力,让数字世界更加生动。该技术如何实现“换表情不换人”?从传统几何变换到深度学习,本文将探索梳理该技术的发展历程和核心技术! 一、基于二维图像的方法:早期探索的初步尝试面部表情所蕴含的丰富情感信息以及在人与人交流中起着关键作用,在面部表情迁移技术的早期探索中,基于几何特征分析的方法占据主导地位,主要依赖于手工特征提取和简单的图像处理技术[1]。例如,通过人工标记关键面部特征点,如眼睛、眉毛、嘴巴的位置和形状,然后基于这些特征点进行几何变换和灰度插值,将源表情的特征叠加到目标面部上。早期这类方法在表情迁移任务中具有一定的优势,处理比较简单,计算量轻,适合静态图像的基础表情迁移。但是,这一方法仅仅考虑了图像像素间的差异,对于处理细节方面的能力相对较弱。这也导致了生成图像的质量不够出色,并且缺乏真实感[2]。 二、基于三维模型的方法:从平面到立体的飞跃三维人脸技术主要依赖于三维人脸重建和三维人脸形变技术,通过输入的图像 与 3D 人脸模型拟合,来克服源图像和目标图像之间的面部定位和姿态差异。然后对其进行形变操作并变换模型纹理,使得模型和目标图像具有相同表情[3]。该方法基本流程如下图所示,主要有以下几个步骤:
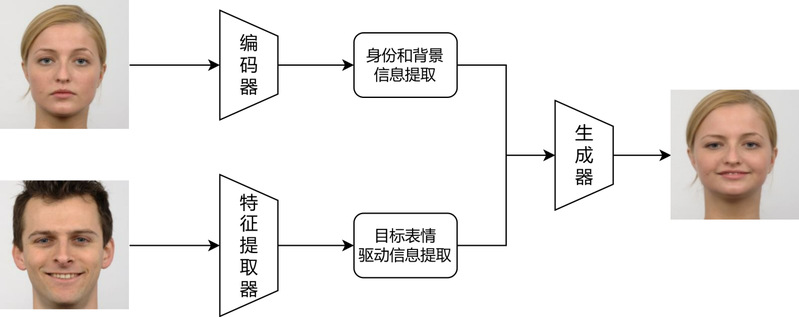
(1) 面部特征识别与定位:首先,利用先进的人脸识别技术对源图像和目标图像进行处理,精准识别并提取面部的关键特征点。这些特征点包括眼睛、鼻子、嘴巴等部位的坐标信息,为后续的三维建模提供基础数据支持。 (2) 三维人脸模型重建:基于提取的特征点,通过 3DMM 建模技术,分别对源图像和目标图像中的人脸进行三维重建。这一过程不仅可以估计出人脸的三维形状,还包括纹理信息的提取,确保模型在细节上高度还原真实人脸的外观。 (3) 三维模型特征映射与形变:在三维模型的基础上,通过参数化调整或非线性变换技术,将目标图像的面部特征自然地映射到源图像的三维模型上。这一过程需要综合考虑面部的比例、光影效果以及肌肉运动规律,确保映射后的特征在源模型上呈现出自然、协调的视觉效果。 (4) 特征融合与图像渲染:最后,将调整后的三维模型重新投影到源图像的平面上,并通过图像渲染技术生成最终的合成图像。渲染过程中会优化光影、色彩和细节,使合成图像在视觉上与原始图像保持一致,同时融入目标图像的特征,实现自然的面部特征替换效果。 在实际应用中,从二维图像中估计三维模型并进行形变的过程通常非常耗费资源和时间,这需要额外的设备支持,例如能够获得深度信息的特殊RGB-D摄像头。尽管降低三维人脸模型的维度可以有效提高计算效率,但这可能会对人脸面部细节的表达产生显著影响。因此,使用该方法时需要在实现实时性和细节保留之间需要进行权衡。对于一些特定应用,该方法可能需要在速度和质量之间进行取舍,根据实际需求来选择合适的方法和设备,在保持一定程度的实时性的同时,尽量减少对人脸细节表达的影响[4]。 三、基于深度学习的方法:数据驱动的技术突破随着深度学习技术在计算机视觉领域的广泛应用,人脸表情迁移迎来了重大突破。卷积神经网络(CNN)和对抗生成网络(GAN)的出现使得计算机能够自动学习面部特征的层次化表示,从而更精准地捕捉和理解人脸表情的本质特征,并且能够生成更为逼真自然的人脸图像[5]。模型的整体架构如下图所示。
该模型主要由三个核心模块构成: (1) 特征编码与身份提取:首先,编码器模块对源人脸图像进行深度特征提取,捕捉人脸的身份特征和背景信息的表征。这一过程通过深度学习模型实现,能够精准提取人脸的独特属性,为后续的特征融合提供基础。 (2) 表情特征提取与驱动:接下来,表情特征提取器模块对目标人脸图像进行处理, 专注于捕捉目标图像中的动态表情特征。这些特征包括面部肌肉的运动模式、表情变化的细微差异等,用于驱动后续的图像生成过程。 (3) 特征融合与图像生成:最后,生成器模块将源图像的身份特征与目标图像的表情特征进行深度融合。通过先进的图像合成技术,生成器将两种特征无缝结合,输出最终的表情迁移图像。生成的图像不仅保留了源图像的身份特征,还自然地融入了目标图像的表情特征,实现高度逼真的表情迁移效果。 在该模型架构中,身份特征信息通常通过两种主要途径实现:一是直接采用预训练的人脸识别模型提取特征,二是直接将源人脸图像输入到生成器中以提供身份信息。身份信息的表征方式在不同模型中大同小异,不同模型的核心差异主要体现在目标表情驱动信息特征的表达方式上。 早期基于深度学习的方法主要是在图像的 RGB 空间上学习目标图像人脸的表情和源图像人脸的身份,如FOMM通过一阶运动模型传递表情。但是这类方法没有对动作和身份进行解耦,因 此以这种方式生成的目标身份往往是源图像和目标图像的平均值,这就是“身份泄露”问题。为了解决这些问题,一些研究者将潜在空间与 GAN 网络结合起来,在潜在空间中操纵表达和身份。如FReeNet分离身份与表情潜在编码,解决身份泄露问题。其他研究者通过建立三维面部潜在表征来解决身份泄漏问题,该模型可以重建面部表情。基本流程主要是:首先对源图像人脸和目标图像人脸通过 3DMM 技术进行系数回归,得到身份、表情和姿态系数。接着将系数进行交叉组合,生成新的目标驱动系数。然后进行 3D 人脸重建,得到源图像人脸和目标驱动人脸的 3D 模型。最后通过 3D 神经渲染技术,将这两种 3D 模型以及源图像人脸的 2D 图像一起输入迁移模型中,生成最终的迁移人脸图像。 基于深度学习的表情迁移是当前的主流方法,能够生成高质量的表情结果,真实度高,对源图像人脸的姿态、表情等处理较好,在表情迁移领域取得了显著的成就。但是需要大量数据集支持训练,依赖情感标签,难以捕捉表情细节,一旦数据集有限很容易过拟合,泛化性差。且大多数的方法都需要一对一训练模型,通用性比较差。同时在训练的过程中容易导致身份泄露问题,表情迁移最终的图像应当身份信息要与原图像人脸保持一致,但是模型未能有效分离目标驱动信息中含有的身份信息,从而在生成图像时产生干扰。而且深度学习模型的训练过程通常需要大量的计算能力,尤其是在处理大规模数据集和复杂神经网络模型架构时。这种高需求可能导致较高的计算开销和较长的训练周期[6]。 四、技术演进与未来展望人脸表情迁移技术经历了从二维几何变换、三维模型重建到深度学习驱动的三次重要跨越。早期基于手工特征的方法虽轻量但缺乏真实感;三维模型技术通过立体建模提升了细节还原能力,却受限于计算效率;而深度学习凭借数据驱动的优势,实现了高保真度的表情迁移,但仍面临泛化性差、身份泄露等挑战。未来,这一技术将在以下方向持续突破: 1. 模型轻量化与实时性优化:随着移动端和边缘计算的普及,如何在低算力设备上实现实时、高质量的表情迁移成为关键。模型压缩、知识蒸馏等技术将助力算法轻量化,而神经渲染(如NeRF)与轻量级GAN的结合可能开辟新的高效路径。 2. 解耦能力与身份保护的强化:身份泄露问题仍是痛点。通过改进潜在空间解耦(如分离身份、表情、光照等因子)、引入更鲁棒的对抗训练策略,或结合3D人脸先验知识,有望实现更精准的身份保留与表情控制。 3. 小样本与自监督学习:减少对大规模标注数据的依赖是突破泛化瓶颈的核心。自监督学习、元学习以及跨域迁移技术可帮助模型从少量数据中提取通用特征,适应多样化的表情场景。 或许未来,每个人都能在虚拟世界中拥有一个“会呼吸的自己”,而技术的使命,正是让这份真实触手可及。从实验室到生活,人脸表情迁移的边界正被不断拓展。技术的终点,或许不是完美复刻人类表情,而是创造一种新的“情感语言”,连接虚拟与现实,传递超越像素的温度。
参考文献 [1] Zhang Q, Liu Z, Guo B, et al. Geometry-driven photorealistic facial expression synthesis [J]. IEEE Transactions on Visualization and Computer Graphics, 2005, 12(1): 48-60. [2] Averbuch-Elor H, Cohen-Or D, Kopf J, et al. Bringing portraits to life[J]. ACM transacions on graphics (TOG), 2017, 36(6): 1-13. [3] Thies J, Zollhofer M, Stamminger M, et al. Face2face: Real-time face capture and reenactment of rgb videos[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2387-2395. [4] Yang C, Yao S Y, Zhou Z W, et al. Poxture: Human Posture Imitation Using Neural Texture[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(12): 8537-8549. [5] Rochow A, Schwarz M, Behnke S. FSRT: Facial Scene Representation Transformer for Face Reenactment from Factorized Appearance, Head-Pose, and Facial Expression Features[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024: 7716-7726. [6] Rochow A, Schwarz M, Behnke S. FSRT: Facial Scene Representation Transformer for Face Reenactment from Factorized Appearance, Head-Pose, and Facial Expression Features[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024: 7716-7726. |