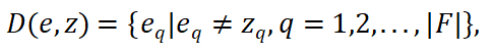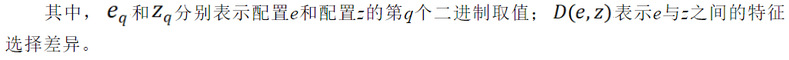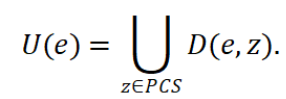| 特征交互:告别软件生产线缺陷定位的昂贵 |
| 发布时间: 2025-04-29 浏览次数: 11 |
|
1.软件产品线缺陷定位的成本为什么那么昂贵? 在软件产品线(Software Product Lines, SPLs)的缺陷定位中,由于大规模系统中程序代码数量庞大且结构复杂,依据测试结果直接定位到具体缺陷语句通常不可行。此外,针对常规系统设计的语句级定位技术在大规模系统上应用时效率极低。因此,定位存在缺陷的特征交互,有助于开发者快速识别导致测试失败的根本原因,从而有效降低调试工作量。然而,随着特征数量的增加,潜在交互数量呈指数级增长,导致搜索空间急剧扩大,给缺陷定位任务带来了严峻挑战。现有方法虽然通过基于可疑特征选择(例如,选取出现在失败配置中但未出现在通过配置中的特征)来构建潜在交互并进行筛查,部分缓解了上述问题,但普遍忽略了特征交互缺陷与测试失败之间的因果关系,导致生成大量冗余交互,进一步扩大了搜索空间,增加了缺陷定位的成本。 针对上述问题,智能算法研究中心提出了一种面向软件产品线的低成本反事实推理缺陷定位方法(CRFL),通过同时减少搜索空间和冗余计算以提升缺陷定位效率。实验结果表明,在小型 SPL 系统(6~9 个特征)上,CRFL 能将搜索空间缩小 51%~73%;在大型 SPL 系统(13~99 个特征)上,搜索空间缩小幅度达到 71%~88%。在运行时间方面,在不降低定位性能的条件下,CRFL 的平均速度约为当前先进方法的 15.6 倍。该工作目前已被软件工程测试领域的顶级会议The ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA,CCF A) 2025会议接收。 2.如何实现低成本的软件产品线缺陷定位 图1展示了来自 Elevator软件产品线系统的部分代码片段中一个功能性特征交互缺陷的示例。抽样得到的产品(配置)及其对应的测试结果如图2所示。
图1 Elevator产品线中一个解释样例
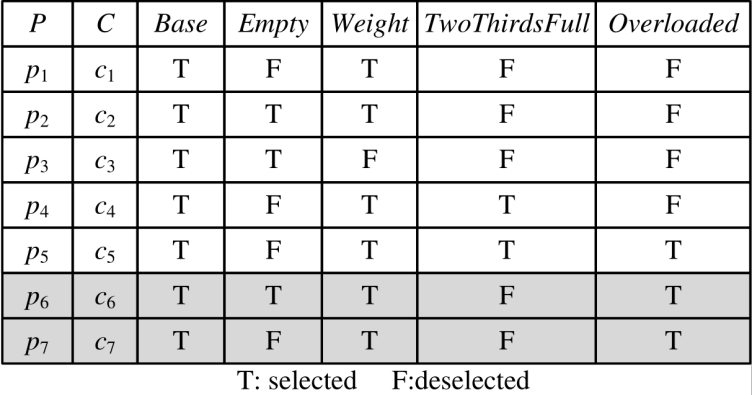
图2 采样的配置和相应的测试结果 在图1中,#ifdef指令通过控制特征的选择或取消选择来实现系统功能。该系统包含五个特征:Base、Empty、Weight、TwoThirdsFull和Overloaded。其中,Base控制基本功能,Empty支持电梯在空载状态下的运行,Weight控制电梯在有载状态下的运行,TwoThirdsFull和Overloaded分别控制当载重达到最大负载的三分之二以及超过最大负载时的运行。第 30 行中的语句weight==maxWeight不符合系统设计逻辑,应修改为weight>=maxWeight。由于该错误属于可变性错误(variability bug),并不会在所有配置中导致缺陷,仅在选择了特征Overloaded的配置中可能引发测试失败。影响第 30 行正常执行的变量为Weight,该变量同时受特征Weight和TwoThirdsFull的控制,表明它们与Overloaded存在交互关系。具体而言,仅当Weight=T、TwoThirdsFull=F 且Overloaded=T 时,配置才会出现失败。需要注意的是,Overloaded只能在Weight被选择的前提下被选择。因此,实际导致缺陷的特征交互为 (-TwoThirdsFull, Overloaded),其中“-”表示特征未被选择。
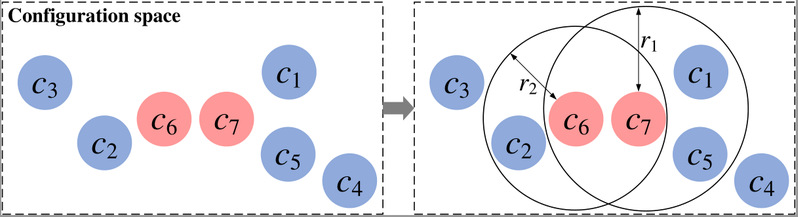
如图3所示,可以在配置空间中表示这些配置,并通过汉明距离等度量方法计算配置间的相似性。据此,可为每个失败配置建立一个搜索半径,用以识别与之相似的通过配置。
此外,我们在实践中观察到,各特征的选择情况与测试结果之间存在一定的相关性。 例如,Base、Weight、TwoThirdsFull和Overloaded与测试结果的相关性较高,而Empty则相关性较低。在本研究中,我们采用对称不确定性(symmetric uncertainty)来量化每个特征与测试结果之间的相关性。该相关性基于特征相对于测试结果的熵与条件熵计算得出。对称不确定性的取值范围为0 到 1,数值越接近 1 表明相关性越强。具体而言,Base、Empty、Weight、TwoThirdsFull和Overloaded与测试结果之间的对称不确定性分别为0.67、0.00、0.50、0.50 和 0.50。因此,可以通过过滤掉如Empty这类无关的低阶特征交互,进一步缩小搜索空间。 3.基于反事实推理的功能型特征交互定位方法(CRFL) 为更好的理解CRFL,有必要对以下关键定义进行描述。 定义1(特征选择差异)对于一个失败配置e和一个通过配置z,特征选择差异指的是e相对于z在特征选择上存在差异的特征集合。
定义2(可疑特征选择)可疑特征选择被定义为,基于一个失败配置e,相对于通过配置集(PCS)生成的所有特征选择差异的并集,即
值得注意的是,特征交互缺陷通常涉及的特征数量不超过六个[1],因此,本研究仅关注 1~7 阶特征交互,遵循了文献[1]中的做法。 定义4(可疑特征交互)若一个待检测的潜在特征交互(FI)同时满足以下两个性质,则被认为是可疑特征交互:
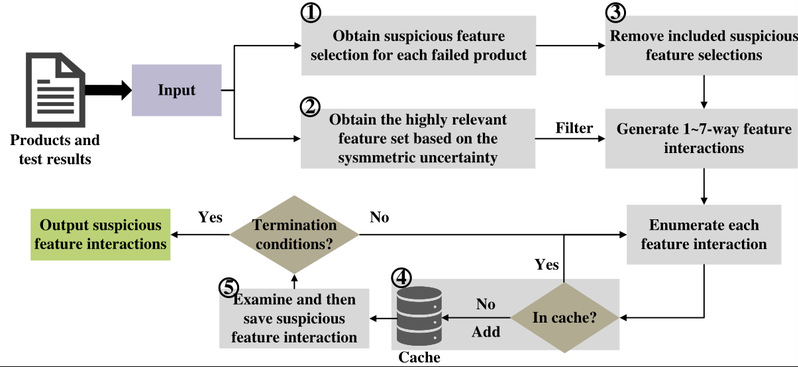
图4展示了CRFL框架,其包括以下五个部分:①基于反事实推理获取可疑特征选择;②基于对称不确定性过滤无关特征交互;③利用包含关系移除包含型可疑特征选择;④通过缓存机制减少冗余特征交互;⑤检查特征交互的可疑性。
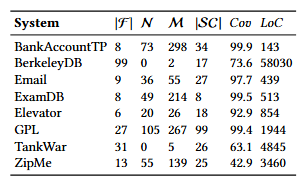
图4 CRFL的框架图 首先,采用反事实推理与对称不确定性,以获得更准确且数量更少的潜在特征交互,从而缩小搜索空间。反事实推理方法在根因定位中已展现出显著优势,尤其因其对数据量要求较低,因而非常适合所关注的问题。此外,对称不确定性作为一种广泛应用于高维特征选择问题的技术,进一步过滤了无关的特征交互。其次,CRFL利用了两项关键发现,以避免对潜在特征交互的可疑性进行重复检测。第一项发现是,可疑特征选择之间存在包含关系,导致潜在特征交互被重复生成;第二项发现是,许多相同的潜在特征交互在检测过程中被多次检验,从而引发重复计算。基于上述两点,CRFL通过避免冗余生成与重复计算,进一步提升了缺陷定位的效率。 4.实验验证 在所介绍的方法中,从两个方面评估CRFL的有效性:效率和准确性。所介绍方法使用了表1中8种真实的Java软件产品线系统以完成实验评估。 表1 所使用的8个Java 软件产品线系统的统计数据
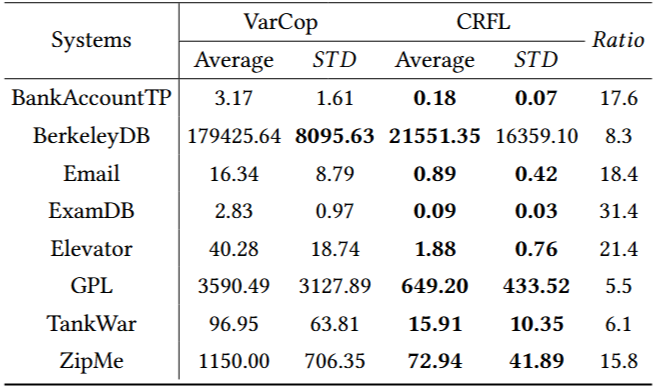
为确保公平,所有的实验均在同一台硬件设备下完成,结果如下。 对于效率,表2展示了 CRFL 和 先进的方法(VarCop, TSE, 2022)在八个系统上的平均运行时间(单位:秒),以及 VarCop 与 CRFL 的运行时间比值。此外,表中还给出了标准差(STD),其中STD越小表示方法的稳定性越高。如表2所示,CRFL在平均运行时间和STD两个指标上均优于VarCop。特别地,CRFL的标准差明显低于VarCop,进一步体现了其稳定性。值得注意的是,CRFL 在所有系统上均显著快于VarCop,提速比范围在 5.5 到31.4之间。具体而言,对于特征数量少于十个的小型系统,如 BankAccountTP、Email、ExamDB和Elevator,CRFL 至少比VarCop快17.6 倍。对于大型系统,如GPL和BerkeleyDB,由于搜索空间呈指数级增长,两个方法均需较长时间,但CRFL 仍快于 VarCop。总体而言,CRFL在小型系统上平均提速 22.2倍,在大型系统上平均提速 8.9 倍。 表2 CRFL与先进方法在运行时间上的比较
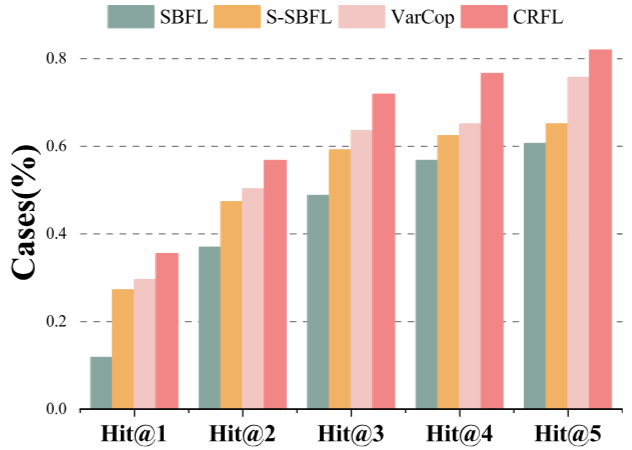
图5 CRFL与基准方法在单缺陷案例上的定位性能比较
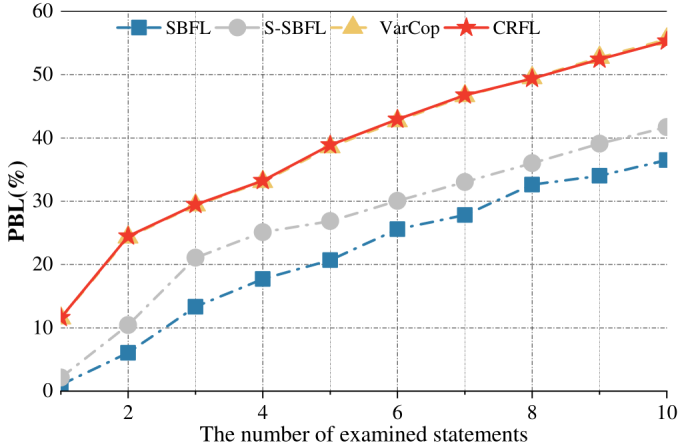
图6 CRFL与基准方法在多缺陷案例上的定位性能比较 所提出工具 CRFL 的源代码及评估中使用的基准测试集已公开,地址为:https://github.com/Songluhaining/CRFL.git。如果你认为这个工作对你有帮助,请考虑引用我们的工作(见参考文献[2]):)。 参考文献 [1]Nguyen T T, Ngo K T, Nguyen S, et al. A Variability Fault Localization Approach for Software Product Lines[J]. IEEE Transactions on Software Engineering, 2022, 48(10): 4100-4118. [2]Haining Wang, Yi Xiang*, Han Huang*, et al. 2025. A Low-Cost Feature Interaction Fault Localization Approach for Software Product Lines. In ISSTA’25. DOI: https://doi.org/10.1145/3728917. [3]Yi Xiang, Han Huang*, Yuren Zhou, et al . 2022. Search-based diverse sampling from real-world software product lines.In ICSE’22. 1945–1957. [4]Kallistos Weis, Leopoldo Teixeira, Clemens Dubslaff, and Sven Apel. 2024. Blackbox Observability of Features and Feature Interactions. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering.1120–1132. [5]Xian-Fang Song, Yong Zhang, Dun-Wei Gong, et al. 2021. A fast hybrid feature selection based on correlation-guided clustering and particle swarm optimization for high-dimensional data. IEEE T. Cybern. 52, 9 (2021), 9573–9586. |