| 对接DeepSeek,部署满血版DeepSeek到底意味着什么? |
| 发布时间: 2025-03-09 浏览次数: 10 |
|
<style type="text/css">
DeepSeek,作为国产大模型中的佼佼者,凭借其强大的性能和显著的算力优势,正在成为众多单位数字化转型的新宠。它不仅在技术上实现了突破,还以更低的算力消耗和更高的效率,为各行业提供了智能化的解决方案。 然而,当越来越多的单位纷纷接入DeepSeek,甚至不惜重金部署本地满血版时,人们不禁要问:这两种方式到底意味着什么呢?为了解答大家的疑问,智能算法研究中心的黄翰教授提出了自己独到的见解。
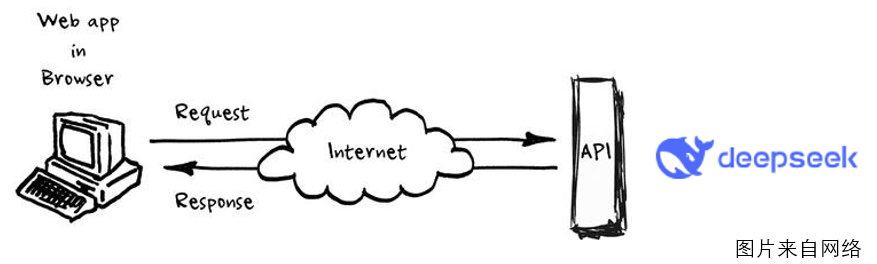
截至目前,很多单位已经开始接入DeepSeek大模型,甚至购买了本地化部署服务。这其实是一种很常见的大模型调用方式。你可以这样理解:这些单位通过调用DeepSeek的API,将获取到的信息发送给大模型,然后得到通用在线版处理后的结果。 当然,还有一些更简单的对接方式,比如直接将DeepSeek的界面嵌入到公司内部。而像我刚才提到的,通过接口的方式对接到DeepSeek的方式,其实是一种相对技术性比较高的版本,也是最常见的方式,相当于通过在线API调用了DeepSeek。
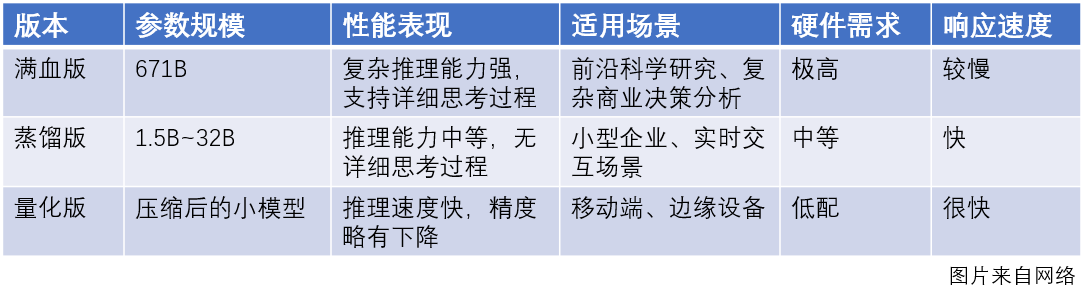
接下来,我们聊聊最近大家热议的“满血版DeepSeek部署”。所谓“满血版”是指DeepSeek声称其拥有671B参数量的模型,代表着最强的推理能力。 部署这样的大模型,意味着你需要在本地运行一个如此庞大的模型。那么,这背后需要多大的算力支撑呢?很多企业会告诉你,算力需求巨大,消耗惊人。你可能需要有一个专业的机房来维护,甚至将服务器托管到有条件的单位或机房。这其实已经有点像云服务了,还能不能算本地部署,就不深究了。 具体来说,部署满血版DeepSeek,本质上是下载离线版的开源大模型,并部署到本地服务器。这和下载其他开源大模型、在本地使用的过程差不多。当然,DeepSeek有自己的优势,网上也有很多报道,我前面也提过。但关键在于,本地使用场景是否能充分发挥这些优势,而不是单纯地下载了满血版就万事大吉。
部署完满血版DeepSeek后,就会面临第二个问题:我们该如何用好这个大模型?有些学校部署是为了教学应用,有些政府部署是为了政务事业,还有一些事业单位是为了提升业务效率。无论是哪种情况,他们都需要根据具体场景设计开发对应的前端软件,以便充分利用DeepSeek固有的能力特性和性能优势。 然而,真正要在场景中用好大模型,尤其是部署了满血版DeepSeek,就必须想清楚一个关键问题:为什么要用满血版?这是一个非常重要且实际的一个问题。满血版意味着最大程度地消耗本地算力资源,那么,你为什么要用这么多代价?为什么要投入大量的算力和运营成本?你的产出和目标是什么?换句话说,我们在使用任何大模型产品时,都需要思考一个问题:为什么要用?而不是为了用而用。 就像过去,家里一定要有一个彩电和一个冰箱才算是小康家庭,那现在是不是不用DeepSeek就落伍了呢?其实不然。关键还是要看用这个大模型到底能做什么,以及是否真正符合你的需求。
不同的需求,对应的大模型配置也各不相同。换句话说,“满不满血”其实取决于你的具体需要。满血版可能适合庞大参数的推理任务,但如果你的需求没那么复杂,低配的大模型或许已经足够。因此,最关键的因素并不在于大模型的规模或算力,而在于你的数据。 数据如何驱动大模型完成高质量的预训练、微调、强化学习,以及奖励机制的执行,这些才是技术的关键。此外,人性化的前端人机交互设计也不可或缺。在业务层面,对场景的深入理解、需求的精准理解,以及针对应用场景的解决方案设计,才是大模型落地的关键。
简而言之,对接DeepSeek,就像去看了《哪吒2》,是一种初步的接触与体验;而部署满血版的DeepSeek,就像买了某品牌的彩电或者冰箱,但还没想清楚如何使用。 以上就是我对对接DeepSeek和部署满血版DeepSeek的见解。如果大家对这个话题感兴趣,欢迎继续探讨! 总编:黄翰 责任编辑:雷墨鹥兮 文字:黄翰、梁靖欣 图片:梁靖欣 校稿:陈嘉慧 时间:2025年2月24日 |