

在大数据时代,人们每天都要面对海量数据和巨量资料,如何存储和传输这些数据成为了一大难题。Protocol Buffers(简称ProtoBuf)是Google公司开发的一种与语言和平台无关语言无关、平台无关、的、可扩展的、序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。用户可以利用ProtoBuf你可以定义数据的结构,然后使用特殊生成的源代码轻松的地在各种数据流中使用各种语言进行来编写和读取结构数据。你,甚至还可以在不破坏由旧数据结构编译的已部署程序的基础上更新数据结构,而不破坏由旧数据结构编译的已部署程序。ProtoBuf目前有两个版本,分别是proto2和proto3,其中最新版本的proto3提供了对C++、C#、Dart、Go、Java、Python、Rust等多种语言的支持。ProtoBuf它性能优异,目前已经被广泛应用于QQ、微信等主流通讯应用工具广泛使用。

ProtoBuf的使用主要分为两步,首先需要使用者在.proto文件中定义消息类型,然后使用protoc编译器根据.proto文件生成相应语言的代码。
图1展示了一个简单的示例。我们定义了一个搜索请求消息,每一个搜索请求都包含了查询字符query、搜索请求返回的页面数量page_number和每页中的结果数量result_per_page。该示例的第一行声明了我们正在使用proto3。如果没有该行,ProtoBuf编译器将默认使用proto2。需注意,此该行一定要位于文件的第一非空及且非注释行。

图1 ProtoBuf搜索请求消息示例
该请求消息示例中的SearchRequest消息定义了三个字段,每一个字段都有一个定义类型、一个字段名称以及字段编号。ProtoBuf提供了大量标准数据类型,其中常用的有:double、float、int32、int64、bool、string、bytes等。此外,message中每个字段都可以指定一个修饰符,proto3默认使用singular修饰符,表示可以有0个或者1个该字段,但不能超过一个。除此之外,还有一种repeated修饰符,表示对应的字段在message中可以有任意数量个,包括0个。

图2 ProtoBuf嵌套类型字段示例
message中包含的字段类型除了默认支持类型外,还支持嵌套类型,即字段类型为所定义的其他message类型。如图2所示,我们在SearchResponse消息中包含了一个repeated修饰的Result类型字段。

图3 ProtoBuf多消息定义示例
在同一个.proto文件中可以定义多个message类型,如图3所示,我们在该.proto文件中定义了SearchRequest和SearchResponse两个消息类型。与此同时,ProtoBuf也可以在不同的.proto文件中定义message,然后通过import语法进行引入。为了防止出现命名冲突的问题,.proto文件将通过引入package语法解决命名冲突的问题。
在解析消息时,如果使用singular修饰符的字段不包含数据,那么ProtoBuf则会给对应字段设定默认值。对于string类型的字段,其默认值为空字符串;对于bytes类型的字段,其默认值为空字节;对于bool类型的字段,其默认值为false;对于数字类型的字段,其默认值为0;对于enums类型的字段,其默认值为第一个定义的枚举类型。此外,对于使用repeated修饰符的字段,其默认值为对应语言的空列表。需要特别注意的是,在proto2中支持指定字段默认值,但在proto3中已经取消了该语法。
在代码注释上,ProtoBuf采用与C/C++相同的 // 和 /**/ 注释格式,如图4所示。

图4 ProtoBuf注释示例
最后,执行图5中的编译指令后,我们就可以在相应的目录下找到生成的对应语言的代码文件。该文件中包含了对不同message的进行定义、修改、访问等操作的方法。图5中的IMPORT_PATH表示import文件的搜索目录,--cpp_out、--java_out、--python_out、--go_out、--ruby_out、--objc_out、--csharp-out、--php_out分别表示生成的C++、Java、Python、GO、Ruby、Objective-C、C#、phpPHP目标代码存放目录。以C++为例,执行该编译指令后会在目标目录生成file.pb.h和file.pb.cc两个文件,file.pb.h中声明了相关类和方法,file.pb.cc中定义了相关类和方法。

图5 ProtoBuf编译指令示例
俗话说得好:“光说不练假把式。”既然ProtoBuf如此强大接下来,那我们就拿ProtoBuf它和与目前最常见的同类型工具JSON进行对比,看看它到底强在哪里。JSON作为一种轻量级的基于文本的编码方法,也可以用来存储结构化数据,它经常被应用在于Client/Server端的通讯中。在对比实验中,我们选择在JSON部分使用由腾讯公司发布的、使用性能较好的腾讯开源的RapidJSON,基于C++编程语言进行测试。
.proto文件如下:

ProtoBuf测试代码如下:
void Protobuf(int times)
{
Person person;
person.set_id(1000000);
person.set_name("XIAOMING");
person.add_phone_num(1008611);
person.add_phone_num(1001011);
string person_string;
cout << "[Protobuf]" << endl << "--编码耗时--" << endl;
cout << "编码次数: " << times << " 数据长度: " << person.SerializeAsString().size() << endl;
auto start = chrono::steady_clock::now();
for (size_t index = 0; index < times; ++index)
{
person_string = person.SerializeAsString();
}
auto end = chrono::steady_clock::now();
cout << "用时: " << chrono::duration<double,std::milli>(end - start).count() << " ms" << endl;
cout << "--解码测试--" << endl;
cout << "解码次数: " << times << " 数据长度: " << person.SerializeAsString().size() << endl;
start = chrono::steady_clock::now();
for (size_t index = 0; index < times; ++index)
{
person.ParseFromString(person_string);
}
end = chrono::steady_clock::now();
cout << "用时: " << chrono::duration<double,std::milli>(end - start).count() << " ms" << endl;
}
JSON测试代码如下:
void Json(int times)
{
Document doc;
doc.Parse("{}");
doc.AddMember("id", 1000000, doc.GetAllocator());
doc.AddMember("name", "XIAOMING", doc.GetAllocator());
Value phone_number(kArrayType);
phone_number.PushBack(1008611, doc.GetAllocator());
phone_number.PushBack(1001011, doc.GetAllocator());
constchar *person_string;
StringBuffer buffer;
Writer<StringBuffer> writer(buffer);
doc.Accept(writer);
person_string = buffer.GetString();
cout << "[JSON]" << endl << "--编码耗时--" << endl;
cout << "编码次数: " << times << " 数据长度: " << buffer.GetSize() << endl;
auto start = chrono::steady_clock::now();
for (size_t index = 0; index < times; ++index)
{
buffer.Clear();
writer.Reset(buffer);
doc.Accept(writer);
}
auto end = chrono::steady_clock::now();
cout << "用时: " << chrono::duration<double,std::milli>(end - start).count() << " ms" << endl;
cout << "--解码测试--" << endl;
cout << "解码次数: " << times << " 数据长度: " << buffer.GetSize() << endl;
start = chrono::steady_clock::now();
for (size_t index = 0; index < times; ++index)
{
doc.Parse(person_string);
}
end = chrono::steady_clock::now();
cout << "用时: " << chrono::duration<double,std::milli>(end - start).count() << " ms" << endl;
}
测试结果如下:
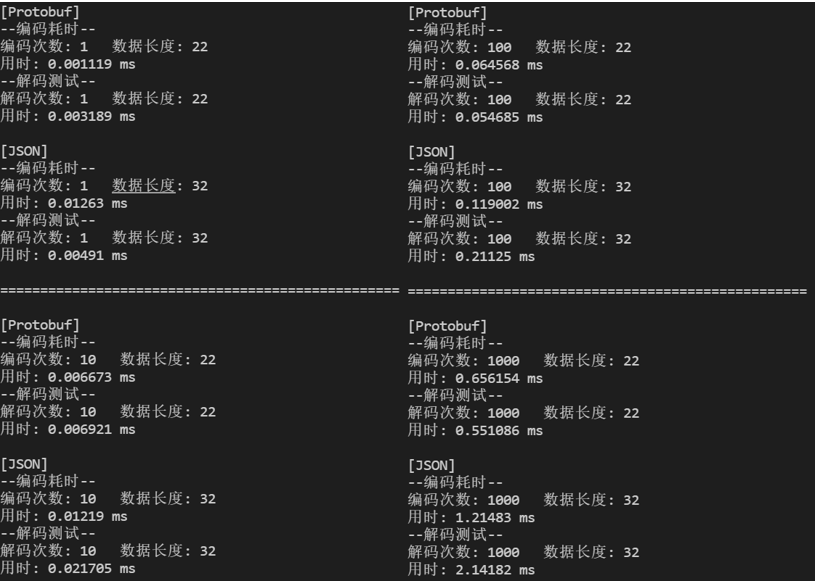
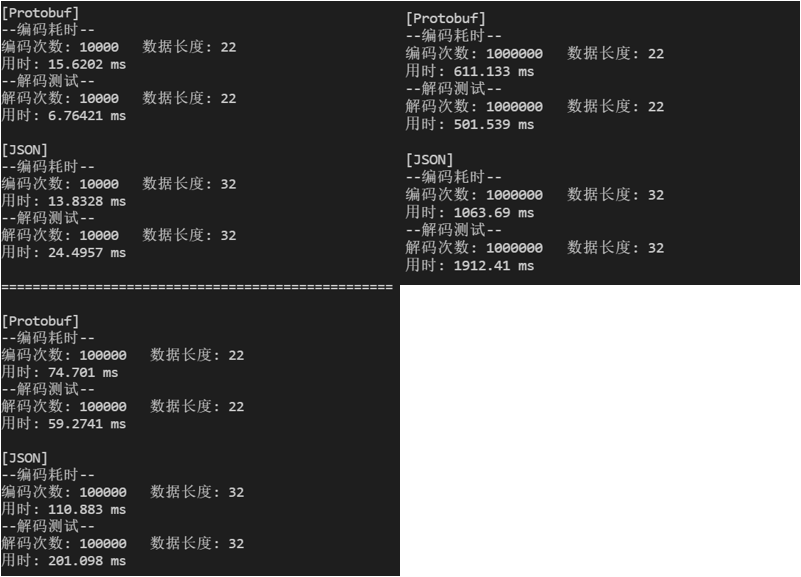
从上述测试结果我们可以看出,整体上ProtoBuf的编码效率为RapidJSON的2.99倍,ProtoBuf其的解码效率为RapidJSON的3.29
。,在存储空间上,ProtoBuf而且存储空间仅为只有RapidJSON的68.75%。当编码和解码频率较低时,二者耗时差异不明显;但当编码和解码频率较高时,ProtoBuf可以节省大量的时间。当数据量较大时,使用ProtoBuf可以有效降低空间需求,在网络传输场景下,可以降低对网络的要求,提高数据传输效率。
总体来说,ProtoBuf序列化和反序列的性能都比较高,编码后的数据大小也不错,编程模式比较友好,简单易学,同时它拥有较为良好完备的文档和示例,有需要的小伙伴放心用起来吧!

总编:黄翰
责任编辑:袁中锦
文字:刘一鸣
图片:刘一鸣
校稿:何莉怡
时间:2021年12月2630日
