
我们常说“互联网时代是大数据的时代”,数据与我们的日常生活息息相关,在我们的衣食住行中都有它的影子。从最初的计算机、摄像头到现在的大数据、人工智能,我们在不断升级操作数据的方式和手段。
到底什么是大数据呢?大数据是指高速(Velocity)涌现的大量(Volume)的多样化(Variety)数据,这就是我们通常提及的3V特性。简而言之,大数据是指越来越庞大、越来越复杂、数据流转越来越快速的数据集,特别是数据源不定的数据集。
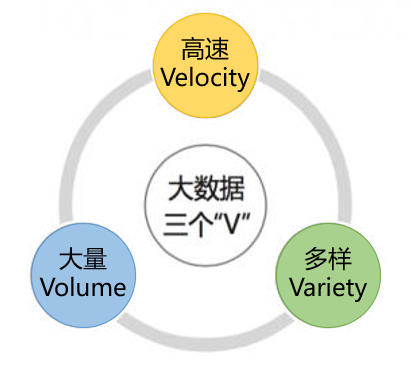
图1 大数据的3V特性
大数据的“大”首先体现在数据量上。在大数据领域中,我们通常需要处理海量的非结构化数据,这些数据的价值是未知的。随着信息化的发展,具有重要价值的知识显式或者隐式地分布在海量数据中,影响了人们获取知识的效率。
海量数据的一部分表现形式主要是非结构化的文本数据。如何把这些非结构化的文本数据转化为结构化的信息,更加准确地抽取出目标信息,并基于这些信息进行进一步的研究和应用,成为了当前的研究热点。而信息抽取,就是解析海量文本数据的主要手段之一。
信息抽取(Information Extraction,IE)是从自然语言文本中抽取出任务所需的特定信息,帮助我们将海量内容进行自动分类、提取和重构的一种技术。
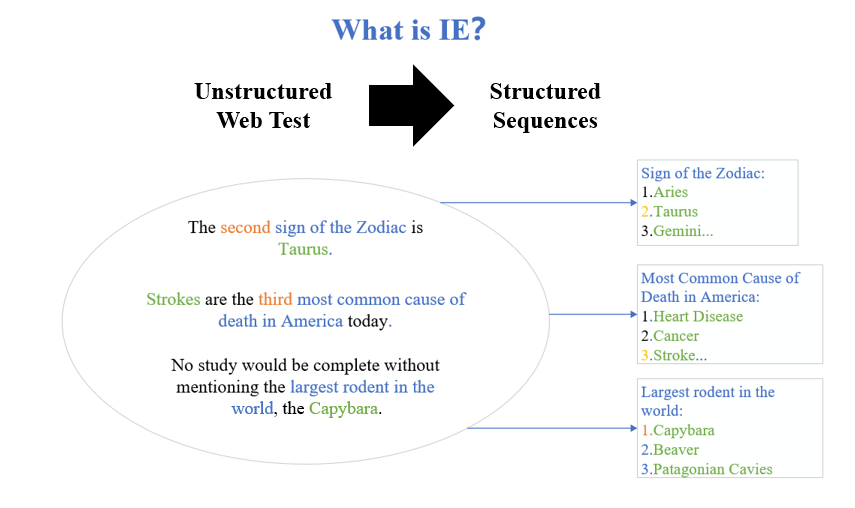
图2 信息抽取的含义
对于非结构化海量文本数据的信息抽取,它的主要任务是自动抽取指定类型的实体、关系和事件等事实信息。总的来说,文本信息抽取主要包括以下三个方面的内容:
(1)自动处理非结构化的自然语言文本数据
(2)根据需要选择性地抽取出文本中的信息
(3)根据抽取的信息形成结构化的数据表示
1993年Hobbs[1] J. Li, A. Sun, J. Han and C. Li, "A survey on deep learning for named entity recognition," IEEE Transactions on Knowledge and Data Engineering, vol. 99, pp. 1-20, 2020.提出信息抽取系统的通用体系结构,他将信息抽取系统抽象成十个模块,如图3所示。
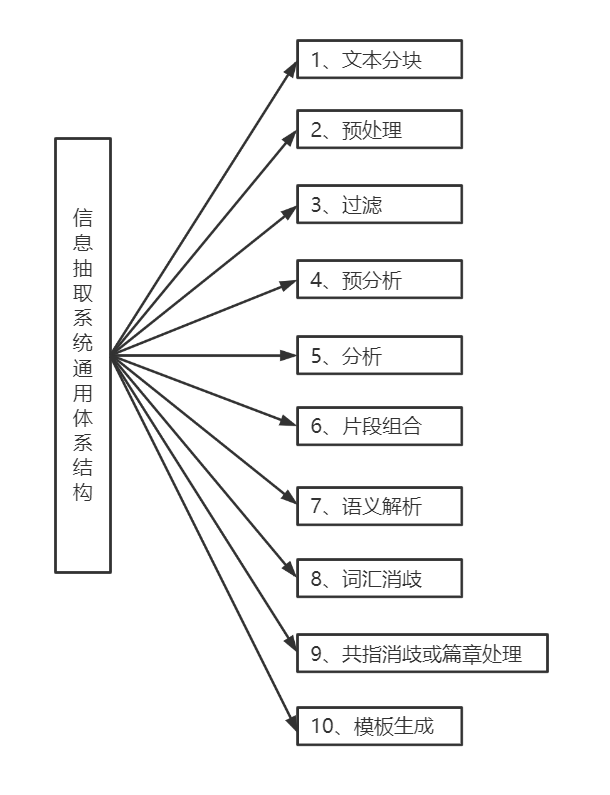
图3 信息抽取系统通用体系结构
而信息抽取中的关键技术也分为多种,可将信息抽取划分为三个子任务:
(1)关系抽取(Relation Extraction,RE)Error: Reference source not found
关系抽取是为了抽取文本中的包含关系,是IE的重要组成部分。它主要负责从海量非结构化文本中抽取出实体之间的语义关系,经常被运用在信息检索、问答系统中。它的主要任务是对给定句子中的两个实体之间的语义关系进行判断,本质上是一个多分类问题。
目前常用的关系抽取方法主要分为5大类:基于模式匹配、基于词典、基于机器学习算法、基于本体和混合的方法。其中基于机器学习算法的方法以自然语言处理技术为基础,相对简单有效,已经成为了目前关系抽取的主流方法。
(2)实体抽取与链指(命名实体识别,Named Entity Recognition,NER)Error: Reference source not found
命名实体识别通常被认为是从原始文本中识别出有意义的实体或者实体指代项的过程,也就是从非结构化文本中标识命名实体并划分到对应的实体类型中。通用任务的实体类型包括人名、地名、组织结构名、日期等。
评价一个命名实体是否被正确识别有两个标准:第一,实体的边界是否正确;第二,实体的类型是否标注正确。命名实体识别的研究方法从早期基于词典和规则的方法,发展到传统机器学习的方法,再到基于深度学习的方法,一直到当下热门的注意力机制、图神经网络等研究方法。
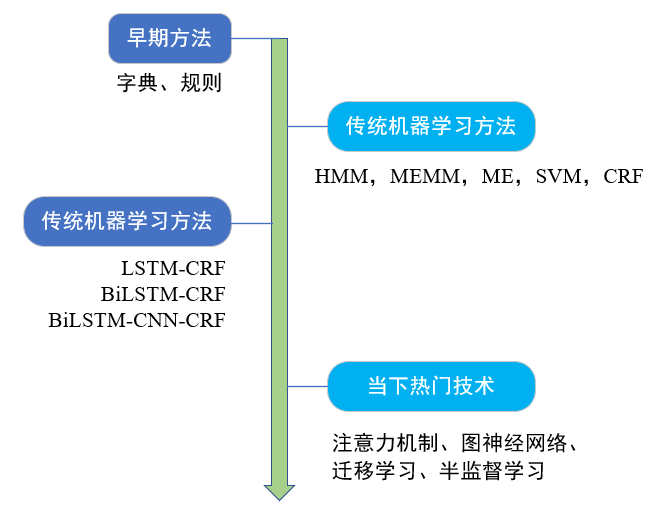
图4 命名实体识别研究方法的发展
(3)事件抽取(Event Extraction,EE)Error: Reference source not found
事件抽取是信息抽取领域中经典的任务之一。事件,是一个概念,指的是若干与特定矛盾相关的事物在某一时空内的运动。“事物”指的是与“问题”、“业务”、“目标”直接或间接相关的人、机构、思想、物质等等。简单来说,比如“老李今天进城”这句话描述的就是一个事件。
事件抽取主要从海量非结构化文本数据中识别出一个与目标相关的事件的重要元素,也就是模式(Schema)。目前,事件抽取一般由两个子任务组成:第一,识别事件并判断类型;第二,识别事件角色。事件抽取解析方法分为流水线型模型和联合模型两种。大部分事件抽取方法都是流水线模型学习方式,先进行事件识别模型的学习,再转入论元角色分类模型的学习。而经仿真验证基于联合模型的学习方式的效果要优于流水线模型学习方式,因此也产生了基于联合模型的事件抽取工作。

信息抽取作为海量内容解析中最常用的自然语言处理技术,是知识图谱、文本结构化等重要NLP任务的主要使用技术,有着不可取代的地位。在海量数据解析的任务中,信息抽取一方面被应用于构建面向特定任务的知识库(知识图谱等),并基于此实现智能检索、智能问答技术;另一方面被应用于发现和识别特定信息,这也是事件抽取的主要目标。
面对在海量数据处理中如此重要的信息抽取,大家是否开始对此感兴趣并打算进行学习呢?希望大家在处理海量数据时,充分利用信息抽取这把利器,实现自己的需求和目标!

参考文献
[1] J. Li, A. Sun, J. Han and C. Li, "A survey on deep learning for named entity recognition," IEEE Transactions on Knowledge and Data Engineering, vol. 99, pp. 1-20, 2020.
[2] W. Xiang and B. Wang, "A survey of event extraction from text," IEEE Access, vol. 7, pp. 173111-173137, 2019.
[3] S. Kumar, "A survey of deep learning methods for relation extraction," arXiv preprint arXiv: 1705.03645, 2017.
[4] J. R. Hobbs, "The generic information extraction system," in Proceedings of the Fifth Message Understanding Conference (MUC-5), 1993, pp. 87-91.
[5]黄翰,陈芳宇,李刚,徐杨,郝志峰.一种面向领域问答的知识图谱构建方法: 202011036897.5[P]. 2021-01-01[2021-08-19].
总编:黄翰
责任编辑:袁中锦
文字:陈芳宇
图片:陈芳宇
校稿:何莉怡
时间:2021年8月19日