2025-03-14
浏览次数:11
近日,我院研究生13篇学术论文被人工智能领域顶会CVPR/ICLR/AAAI(2025)成功录用,充分展现了我院在人工智能领域前沿研究方向取得的显著进展以及研究生学术创新能力培养方面的成效。
计算机视觉与模式识别会议(CVPR),是计算机视觉领域的顶级国际会议。CVPR采用严格的同行评审机制,吸引了来自全球顶尖高校、研究机构以及工业界的广泛投稿,其论文在计算机视觉和人工智能领域具有深远的影响。在中国计算机学会CCF推荐会议榜单中,CVPR属于A类会议,与ICCV、ECCV并称为计算机视觉领域的三大顶级会议,代表了该领域的最高学术水平。今年的CVPR(2025)会议共收到超过12,000篇有效投稿,录用率约为25%。我院录用率约为35%。
国际表征学习大会(ICLR),是深度学习领域的顶级会议。ICLR采用开放审稿机制,吸引全球顶尖高校和研究机构的投稿,其论文在人工智能领域具有重要影响。在中国计算机学会CCF推荐会议榜单中,ICLR同属A类会议,与NeurIPS、ICML并列,代表该领域的最高学术水平。今年的ICLR 2025会议共收到接近11,500篇有效投稿,录用率约32.08%。我院录用率约为75%。
美国人工智能协会(AAAI),是人工智能领域的国际顶级会议,是CCF-A类会议,是全球人工智能领域历史最悠久、覆盖范围最广的学术会议之一,它在Google Scholar的顶级AI出版刊物列表中的H5指数排名第四。此次AAAI会议收到有效稿件12957篇,录用3032篇,录取率为23.4%。我院录用率约为40%。
01 Monocular and Generalizable Gaussian Talking Head Animation
作者:龚圣杰(华南理工大学),李豪杰(华南理工大学),唐佳鹏(慕尼黑工业大学),胡东鸣(华南理工大学)、黄双萍*(华南理工大学)、陈浩(华南理工大学)、陈添水(广东工业大学)、刘卓蔓(香港理工大学)
论文简介
在本研究中,我们提出了一种单目且可泛化的高斯说话头像动画方法(Monocular and Generalizable Gaussian Talking Head Animation,简称MGGTalk)。该方法仅需单目数据集,并能够在未经个性化重新训练的情况下泛化到未知身。相比于以往基于三维高斯溅射(3D Gaussian Splatting,3DGS)的方法,这些方法通常需要依赖稀缺的多视角数据集或进行繁琐的个性化训练/推理,MGGTalk 使得这一技术更具实用性和广泛适用性。然而,在缺乏多视角和个性化训练数据的情况下,几何和外观信息的不完整性构成了重大挑战。为了解决这些挑战,MGGTalk 利用深度信息面部对称特性来增强几何和外观特征。首先,我们基于深度估计获得的逐像素几何信息,结合对称操作和点云过滤技术,以确保 3DGS 具有完整且精确的位置参数。随后,我们采用一种带有对称先验的两阶段策略来预测其余的 3DGS 参数。先预测源图像中可见面部区域的高斯参数,再利用这些参数来优化不可见区域的高斯参数预测。大量实验表明,MGGTalk 在多个指标上均超越了现有最先进的方法,展现了优秀的性能。

02 MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving
作者:张志远(华南理工大学)、李晓帆(百度)、徐之昊(华南理工大学)、彭文杰(华南理工大学)、周子键(伦敦国王学院)、史淼晶(同济大学)、黄双萍*(华南理工大学)
论文简介
自动驾驶视觉问答(AD-VQA)旨在根据给定的驾驶场景图像回答与感知、预测和规划相关的问题,这类问答严重依赖模型的空间理解能力。之前的工作通常通过坐标的文本表示来表达空间信息,导致视觉坐标表示和文本描述之间的语义鸿沟。这种疏忽阻碍了空间信息的准确传递,并增加了表达负担。为了解决这个问题,本文提出了一种新的基于标记的提示学习框架MPDrive,用简洁的视觉标记来表示空间坐标,确保语言表达的一致性,并提高自动驾驶视觉问答中视觉感知和空间表达的准确性。通过利用检测专家用数字标签覆盖目标区域来创建标记图像,将复杂的文本坐标生成转换为直接的基于文本的视觉标记预测。融合原始图像和标记图像作为场景级特征,并将其与检测先验相结合得到实例级特征。通过结合这些特征,构建了双粒度视觉提示,刺激了LLM的空间感知能力。大量实验表明,MPDrive 在多个指标上均超越了现有最先进的方法,展现了优秀的性能。

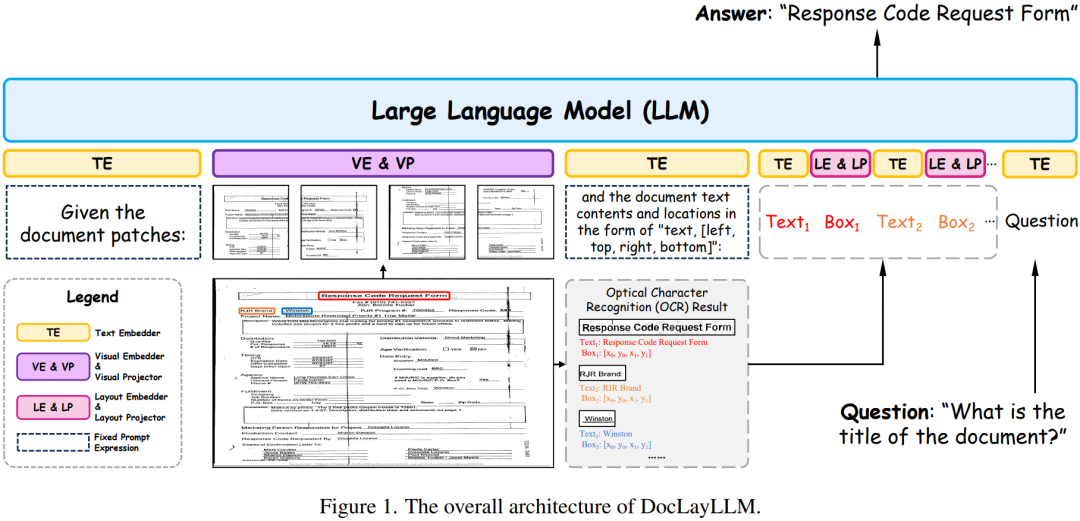
03 DocLayLLM: An Efficient Multi-modal Extension of Large Language Models for Text-rich Document Understanding
作者:廖文辉 (华南理工大学), 汪嘉鹏 (华南理工大学), 李鸿亮 (华南理工大学), 汪诚愚 (阿里云计算有限公司), 黄俊 (阿里云计算有限公司), 金连文* (华南理工大学)
论文简介
视觉富文档理解是指对具有复杂版面布局的文档进行解析与理解的过程,这一过程需要融合多种模态的信息。然而,该领域在面对不同布局和类型的文档时,面临着通用性和泛化性的挑战。为了解决这一问题,我们提出了DocLayLLM,通过在大语言模型(LLM)中引入轻量化的视觉标记和二维位置标记,充分发挥了LLM的通用性与泛化能力,同时实现了高效的多模态扩展。此外,我们结合思维链技术,提出了思维链预训练和思维链退火的训练方法,显著提升了模型的训练效率和性能表现。实验结果表明,在使用更少计算资源的情况下,我们的方法在性能上超越了现有的其他文档理解大模型。
04 Guiding Human-Object Interactions with Rich Geometry and Relations
作者:薛梦晴(华南理工大学),刘翼飞(华南理工大学),郭岭(华南理工大学),黄少立(腾讯 AI Lab),丁长兴*(华南理工大学)
论文简介
该论文提出了一种基于扩散模型的、文本驱动的“人-物交互”(HOI)动作生成框架ROG。该方法通过对HOI固有的时空关系进行建模,提升了动作生成的真实感。为实现高效的物体表征,我们从物体网格中筛选出了边界敏感且几何细节丰富的关键点,确保对物体几何结构的全面描述。我们使用这种表征构建了交互距离场(IDF),从而捕捉稳健的HOI动态特性。此外,我们提出了融合时空注意力机制的关系扩散模型,使其能够深入理解复杂的HOI关联。该模型通过优化生成动作的IDF特征,引导运动生成过程产生关系感知且语义对齐的动作。实验评估表明,ROG在HOI生成的真实性和语义准确性等方面显著优于现有最先进的方法。

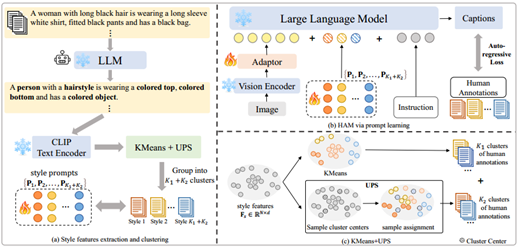
05 Modeling Thousands of Human Annotators for Generalizable Text-to-Image Person Re-identification
作者:江佳瑜(华南理工大学),丁长兴*(华南理工大学),谭文韬(华南理工大学),王骏宏(华南理工大学),陶金(华南理工大学),徐向民(华南理工大学)
论文简介
该论文提出了一种名为“人类标注者建模”(HAM)的方法,旨在为“文本-图像”跨模态行人重识别(ReID)任务解决文本标注的多样性难题。现有的多模态大语言模型(MLLMs)在生成图像描述时通常风格较为单一,限制了其在实际应用中的泛化能力。为解决这一问题,HAM对人工标注数据集中数千个人类标注者分别进行建模,用于丰富MLLMs生成的文本描述的多样性。该方法首先从人工文本描述中提取风格特征,并对这些特征进行聚类,最终通过提示学习使MLLM具备对不同风格指令的跟随能力。随后,我们利用均匀原型采样(UPS)方法,在定义的风格特征空间中进行均匀采样,以捕捉更广泛的人类标注风格,进一步增强了MLLMs在生成文本描述方面的风格多样性。实验结果表明,我们构建的HAM-PEDES数据集在多个基准测试上表现出了优越性能,大幅度提高了“文本-图像”跨模态行人重识别模型的泛化能力,显著降低了模型对大规模人工标注的依赖,为未来的研究提供了新的视角和方法。
06 Effortless Active Labeling for Long-Term Test-Time Adaptation
作者:王国威(华南理工大学),丁长兴*(华南理工大学)
论文简介
该论文提出了一种基于高效主动学习的测试时自适应方法,其核心在于如何选择最有价值的样本进行标注。我们提出了一种基于特征扰动的策略,通过衡量样本在轻微扰动下的预测置信度的变化幅度来识别最有价值的样本。这主要是因为:那些位于源域和目标域数据分布边界上的样本最有信息量,也最容易通过单步优化来学习。此外,该论文还引入了一种基于梯度范数的去偏策略,通过动态权重平衡标注样本和未标注样本对模型优化的影响。在多个主流数据集上的大规模实验表明,我们的方法在显著降低标注成本的同时,还取得了优于现有最先进方法的性能。例如,在ImageNet-C数据集上,该方法在每个批次仅标注一个样本的情况下,平均错误率比基线方法降低了6.8%。即使每五个批次仅标注一个样本,该方法仍然保持了优越的性能。

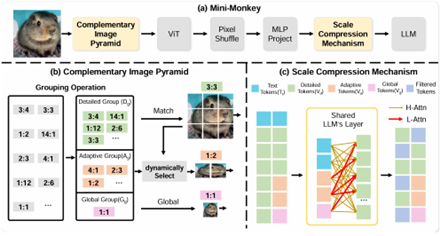
07 Mini-Monkey: Alleviating the Semantic Sawtooth Effect for Lightweight MLLMs via Complementary Image Pyramid
作者:黄明鑫(华南理工大学)、刘禹良(华中科技大学)、梁定康(华中科技大学)、金连文*(华南理工大学)、白翔(华中科技大学)
论文简介
针对多模态大模型中切分策略导致的语义破坏问题,本文提出了一种可插拔的自适应图像金字塔模块(Complementary Image Pyramid, CIP),以提升处理高分辨率图像的能力。CIP通过生成互补的图像层次结构,不仅能够提供精细的局部特征,同时也兼顾了整体图像的全局信息,有效地缓解了因图像切分造成的不连贯性。此外本文还引入了尺度压缩机制(Scale Compression Mechanism, SCM),实现了计算资源的有效利用。结合CIP和SCM,作者构建了一个轻量化的多模态大模型——MiniMonkey。实验结果表明,MiniMonkey无论是在通用场景还是复杂的文档图像分析中均表现出优异的性能,特别是在OCRBench上,Mini-Monkey获得了806分,优于InternVL-2-8B等同期更大参数量的大模型。CIP还具有广泛的适用性,可以无缝集成到多种不同架构的多模态大模型中并提升其性能,为高分辨率图像处理提供了全新的视角和技术路径。
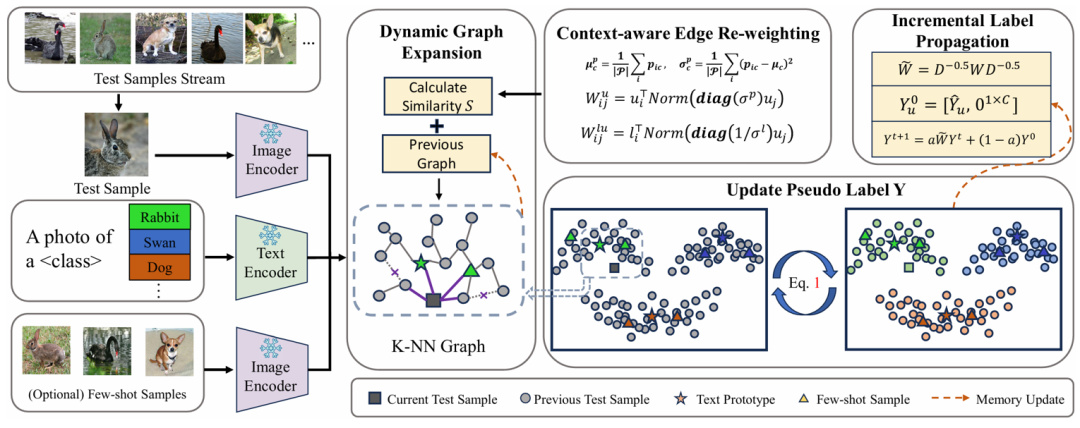
08 Efficient and Context-Aware Label Propagation for Zero-/Few-Shot Training-Free Adaptation of Vision-Language Model
作者:李昱澍(华南理工大学)、苏永怡(华南理工大学)、Adam Goodge(新加坡科技研究局)、贾奎(香港中文大学(深圳))、徐迅(新加坡科技研究局)
论文简介
视觉-语言模型(VLMs)通过利用大型预训练模型来处理各种下游任务,彻底改变了机器学习。尽管标签、训练和数据效率有所提高,但许多最先进的模型仍然需要针对特定任务的超参数调整,并且无法充分利用测试样本。为了克服这些挑战,我们提出了一种基于图的高效适应和推理方法。我们的方法动态地在文本提示、少样本示例和测试样本上构建图,使用标签传播进行推理,无需针对特定任务的调整。与现有的零样本标签传播技术不同,我们的方法不需要额外的无标签支持集,并通过动态图扩展有效地利用测试样本流形。我们进一步引入了一种上下文感知特征重加权机制,以提高任务适应准确性。此外,我们的方法支持高效的图扩展,实现实时归纳推理。在细粒度分类和分布外泛化等下游任务上的广泛评估,证明了我们方法的有效性。
09 On the Adversarial Risk of Test Time Adaptation:An Investigation into Realistic Test-Time Data Poisoning
作者:苏永怡(华南理工大学)、李昱澍(华南理工大学)、刘南清(西南交通大学)、贾奎(香港中文大学(深圳))、杨旭雷(新加坡科技研究局)、Chuan-Sheng Foo(新加坡科技研究局)、徐迅(新加坡科技研究局)
论文简介
测试时自适应(Test-time adaptation, TTA)在推理阶段利用测试数据更新模型权重,以提升其泛化能力。然而,这一实践也使TTA面临对抗性风险。现有研究表明,当TTA在更新过程中受到精心构造的对抗性测试样本(即测试时投毒数据)的影响时,其在正常样本上的性能可能会下降。然而,若投毒数据的生成依赖于过于强烈的假设,那么所感知的对抗性风险可能被夸大。在本研究中,我们首先回顾了测试时数据投毒的现实假设,包括白盒攻击与灰盒攻击、对正常数据的访问权限、攻击顺序等。随后,我们提出了一种更有效且更具现实性的攻击方法,该方法能够在无法访问正常样本的情况下生成投毒样本,并推导出一种有效的分布内攻击目标函数。此外,我们设计了两种针对TTA的攻击目标函数。通过对现有攻击方法的基准测试,我们发现TTA方法的鲁棒性比此前研究所认为的更强。最后,我们探讨了有效的防御策略,以推动对抗性鲁棒TTA方法的发展。
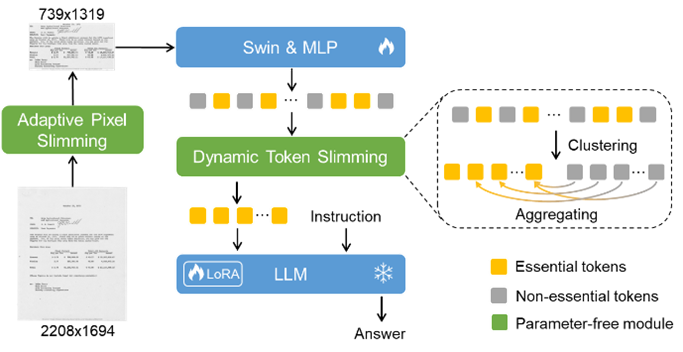
10 DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
作者:张家鑫(华南理工大学)、杨文韬(华南理工大学)、赖松轩(华为云)、谢泽澄(华为云)、金连文*(华南理工大学)
论文简介
多模态大语言模型(MLLMs)近期取得快速发展,但其在视觉文档理解(VDU)任务中仍面临显著局限:输入分辨率不足导致细粒度信息丢失,而高分辨率输入导致的高冗余像素及低效视觉token压缩又对模型效率和长上下文建模能力提出了巨大的挑战。此外,当前方法普遍采用的固定分辨率压缩易引发文本形变。针对这些问题,本文提出DocKylin模型,通过动态视觉压缩技术实现高效的文档图像去冗余。该模型基于无参数自适应机制,结合梯度分析和规则设计在像素层面裁剪冗余区域、支持动态分辨率编码以适配文档长宽比特性,并通过智能聚类筛选关键视觉token,显著减少冗余计算同时保留核心特征。实验验证DocKylin在主流基准测试中性能优势突出,且模块化设计可便捷迁移至其他MLLMs,为复杂文档理解任务提供兼顾效率与精度的创新方案。
11 Revisiting Tampered Scene Text Detection in the Era of Generative AI
作者:曲晨帆(华南理工大学)、钟亦武(香港中文大学)、郭丰俊(上海合合信息科技股份有限公司)、金连文*(华南理工大学)
论文简介
当下生成式AI高速发展的时代,新的文字图像编辑算法层出不穷。然而现有文字图像篡改检测方法仅仅对训练集见过的篡改方法表现好,检测训练集未见过的文字编辑模型生成的篡改文字时性能会剧烈下降。这为信息安全带来了巨大隐患。本文针对对未知AIGC文字篡改方法进行泛化的问题,构建了包含8种AIGC篡改手法的新数据集,首次能同时满足对模型跨篡改生成方法及跨图像风格的评估。针对高质量AIGC文本篡改数据获取成本高数量少的问题,本文提出纹理抖动训练范式,大幅度解决了高质量训练数据匮乏的问题并引导模型通过关注纹理异常提升跨域泛化性。本文还提出差异感知建模框架进一步提升了模型对未知AIGC方法篡改的泛化性。

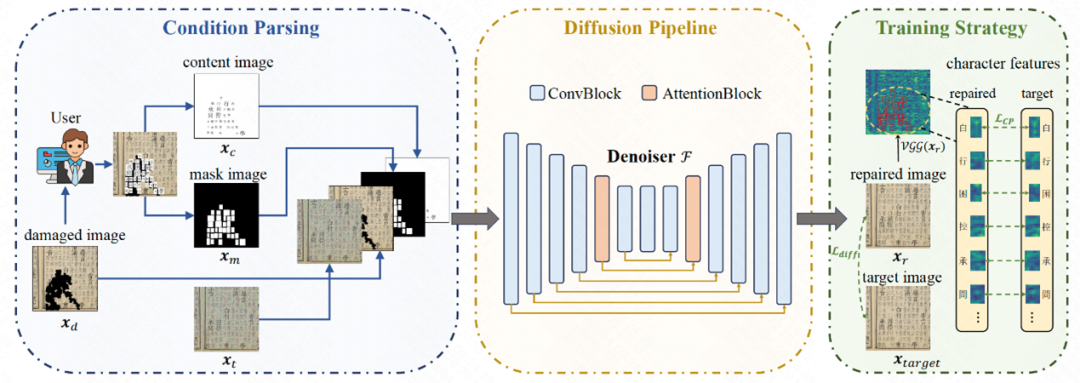
12 Predicting the Original Appearance of Damaged Historical Documents
作者:杨振华(华南理工大学)、彭德智(华南理工大学)、施永鑫(华南理工大学)、张宇一(华南理工大学)、刘崇宇(华南理工大学)、金连文*(华南理工大学)
论文简介
古籍文档蕴含丰富的文化信息,但随着时间的推移,它们遭受了严重的损害,包括字符缺失、纸张损坏和墨迹侵蚀。然而,现有的文档处理方法主要聚焦在二值化、增强等操作,而忽视了对这些损坏的修复。为此,我们提出了一项新的任务,称为古籍文档修复(Historical Document Repair,HDR),旨在预测损坏古籍的原始外观。为填补该领域的空白,我们构建了一个大规模数据集 HDR28K,并提出了一种基于扩散模型的修复网络 DiffHDR 用于古籍文档修复。具体而言,HDR28K 包含 28552 对损坏-修复图像,并提供字符级标签和多种风格的损坏。此外,DiffHDR 在扩散模型的基础上,融入了语义和空间信息,并精心设计了字符感知损失,以确保上下文连贯性和视觉一致性。实验结果表明,DiffHDR 远超现有方法,并在处理真实受损文献时表现出卓越的性能。值得注意的是,DiffHDR 还可以扩展到文档编辑和文本块生成,展现出极高的灵活性和泛化能力。我们相信,这项研究可以开创文档处理的新方向,并为珍贵文化和文明的传承作出贡献。
13 GAS: Generative Activation-Aided Asynchronous Split Federated Learning
作者:杨嘉镕(华南理工大学)、刘元(华南理工大学)
论文简介
分割联邦学习将模型分割部署于客户端与服务器端,并进行协同训练,有效降低客户端的计算负担。近期的分割联邦学习研究假设客户端和服务器之间的激活值和客户端模型同步传输。然而,由于客户端异构性导致的算力差异和网络波动,服务器往往面临异步到达的激活值和客户端模型,降低了分割联邦学习的训练效率。针对这一挑战,本研究提出异步分割联邦学习框架,其中在服务器端嵌入了激活缓冲区和模型缓冲区,分别用于管理异步传输的激活值和客户端模型。基于动态更新的激活值分布,我们开发自适应激活生成算法,该算法通过偏差感知机制生成补偿激活值,确保全局模型更新的准确性。理论分析方面,推导出更紧密的理论收敛边界。实验结果证明了所提方法的有效性。

(图文/黄双萍、金连文、刘元、丁长兴,初审/燕维英,复审/曾抒姝,终审/李石槟)